



Если Вы — департамент Москвы, то выпустить ролик на федеральном канале и попросить людей прислать изображения счетчиков — не очень большая проблема. Но что делать, если Вы — маленький стартап, и сделать рекламу на телеканале не можете? Как получить 50 000 изображений счетчиков в таком случае? На помощь приходит Яндекс. Толока!
Яндекс.Толока — краудсорсинговая платформа, на которой люди со всего мира выполняют несложные задания, получая за это деньги. Например, толокеры могут находить пешеходов на изображении, обучать голосовых помощников и многое другое. При этом разместить задания на Толоке могут не только сотрудники Яндекса, но и любой желающий.
Постановка задачи
Итак, мы хотим создать нейронную сеть, которая по фотографии будет определять показания счетчиков. С чего начать, какие данные нам нужны?
Посовещавшись с коллегами, мы приходим к выводу, что для создания MVP нам нужно 1000 изображений счетчиков. При этом для каждого счетчика мы хотим знать текущие показания, а также координаты окна с цифрами.

Если Вы еще никогда не работали с Толокой, то советую прочитать статью, которую я писал год назад. Так как текущая статья будет технически более сложная, то некоторые моменты, подробно описанные в прошлой статье, я буду опускать.
Благодарности:
Прошлая статья стала ТОП-2 в рейтинге статей от сообщества ODS. Спасибо, что комментируете и ставите плюсы!)
Часть 1. Получение изображений
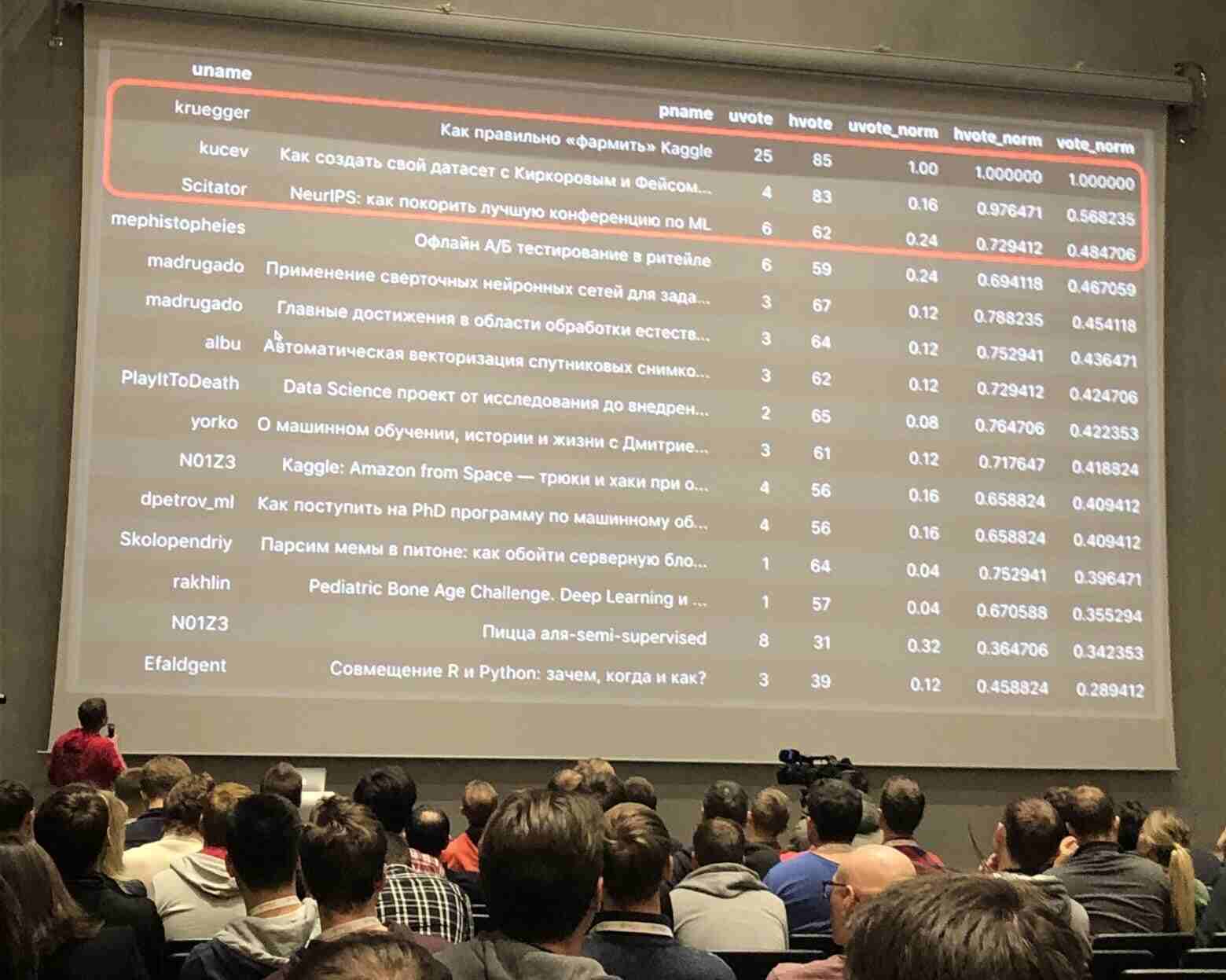
Что может быть проще? Всего лишь нужно попросить человека открыть приложение Яндекс. Толока на своем телефоне и сфотографировать свой счетчик. Если бы я не работал несколько лет с Толокой, то моя инструкция звучала бы так: "Вам нужно сфотографировать свой счетчик воды (горячей либо холодной) и прислать нам изображение".
К сожалению, при такой постановке задачи хороший датасет собрать не получится. Все дело в том, что данное ТЗ люди могут интерпретировать по-разному, так как в инструкции нет четких критериев правильно выполненного задания. Толокеры могут прислать:
- размытые изображения;
- изображения, на которых не видно показаний;
- изображения с несколькими счетчиками.
В блоге Толоки есть отличный туториал, посвященный написанию инструкций. Следуя ему, у меня получилась такая инструкция:


Интерфейс задания пишется всего в 2 строки!
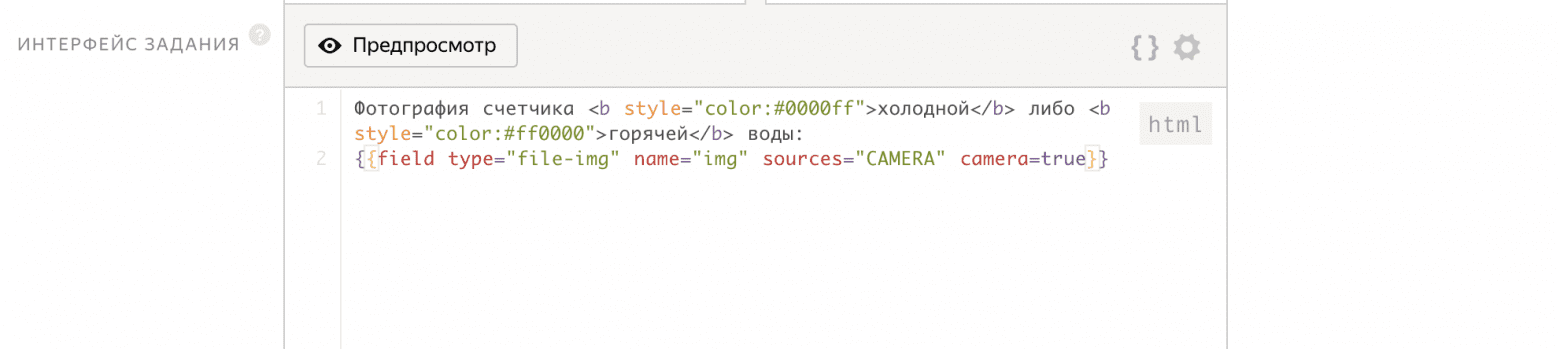
При создании пула указываем время на выполнение задания, отложенную приемку и цену за задание 0.01 $.
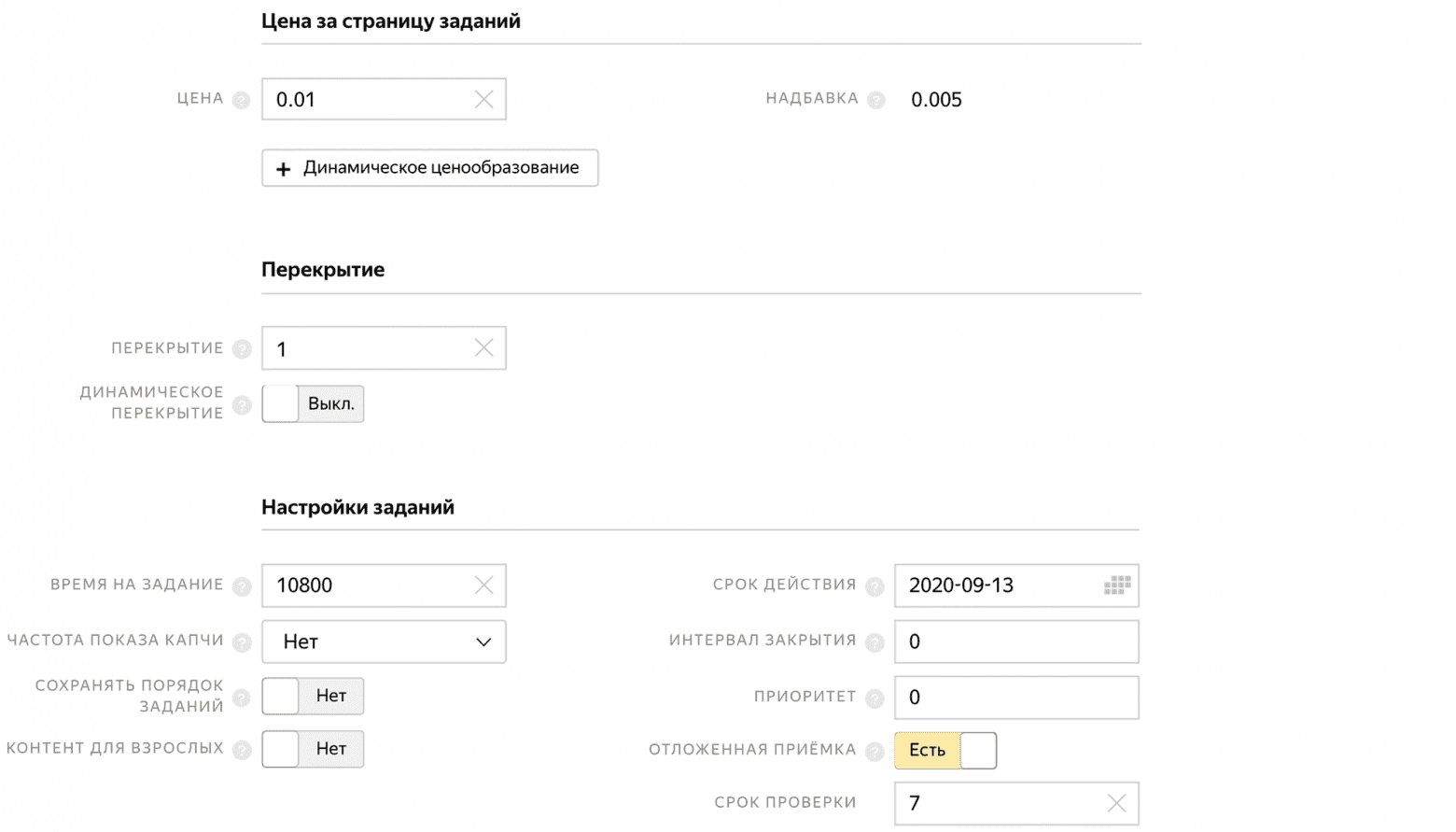
А чтобы люди по несколько раз не выполняли задание и не отправляли одинаковые фотографии, в блоке контроля качества запрещаем повторное выполнение задания.

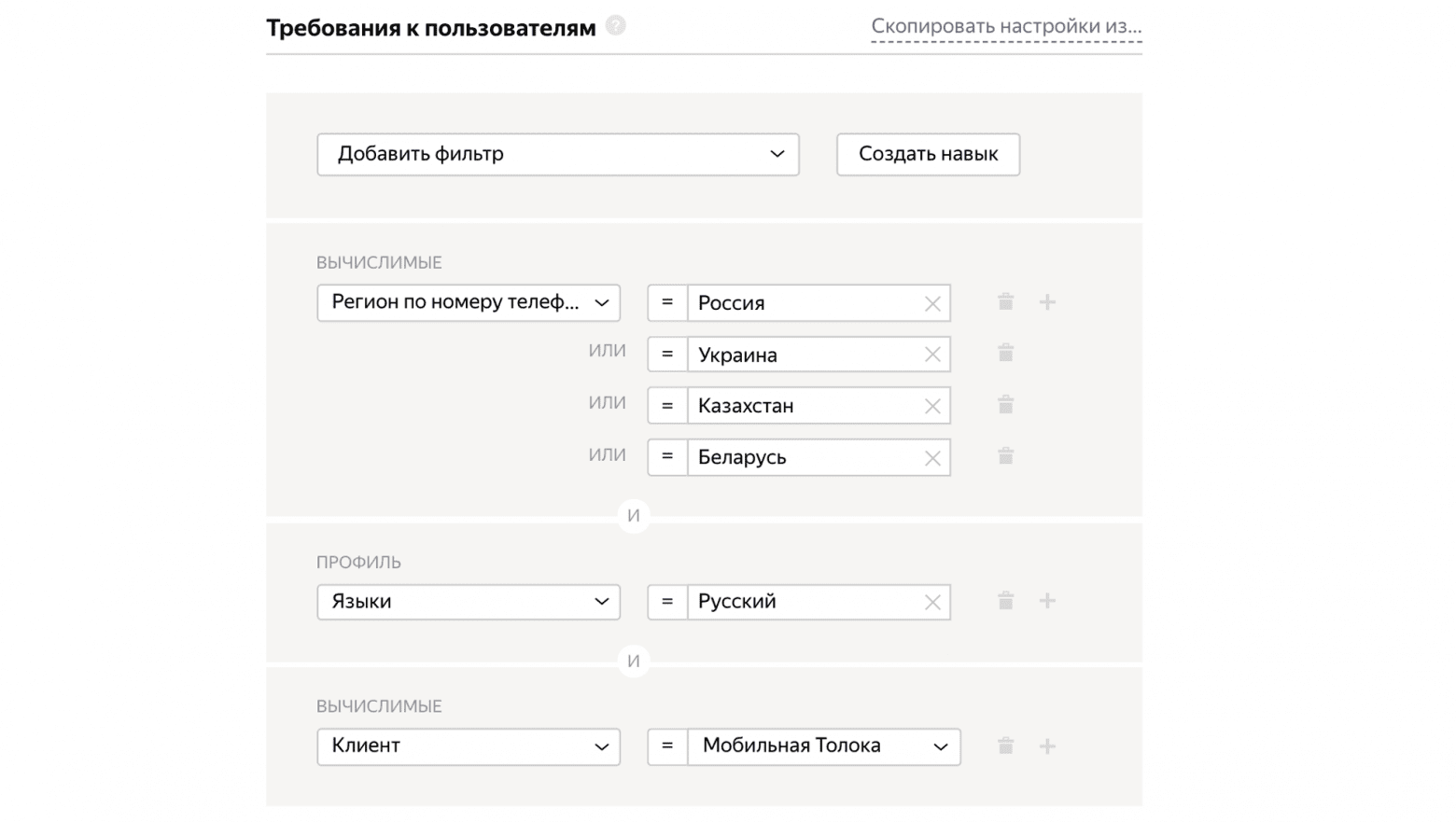
Укажем, что нам нужны русскоговорящие пользователи, которые выполняют задание через мобильное приложение Яндекс.Толока.
Загружаем задания в пул.

Запускаем пул, радуемся и ждем ответов пользователей! Вот так выглядит наше задание со стороны толокера:
Часть 2. Приемка заданий
Подождав пару часов, видим, что толокеры выполнили задание. Так как при отложенной приемке награждение выплачивается исполнителю не сразу, а замораживается на балансе у заказчика, то теперь мы должны проверить все присланные изображения. У добросовестных исполнителей принять задания, а исполнителям, которые прислали неподходящие под критерии изображения, отказать и написать причину отказа.
Если бы изображений было не очень много, то мы бы могли сами просмотреть и проверить все присланные изображения. Но мы же хотим получить тысячи и десятки тысяч изображений! Проверка такого объема заданий потребует существенного количества времени. Плюс данный процесс требует непосредственно нашего участия.
На помощь снова приходит Толока! Мы можем создать новое задание "Проверка изображений счетчиков" и просить других толокеров отвечать, подходит ли изображение под наши критерии или нет. Настроив один раз процесс, мы получим полностью автоматический сбор и валидацию данных! При этом сбор данных легко масштабируется, и, если нам нужно будет увеличить размер датасета в несколько раз, достаточно лишь нажать пару кнопок.
Звучит потрясающе и грандиозно, не правда ли?
Тогда пора претворять задумку в жизнь!
Первым делом определим критерии, по которым будем считать фотографию хорошей.
Фотография хорошая, если:
- На фотографии ровно один счетчик холодной либо горячей воды;
- Показания на счетчике отчетливо видны.
В иных случаях фотографию считаем плохой.
С критериями разобрались, теперь пишем инструкцию!

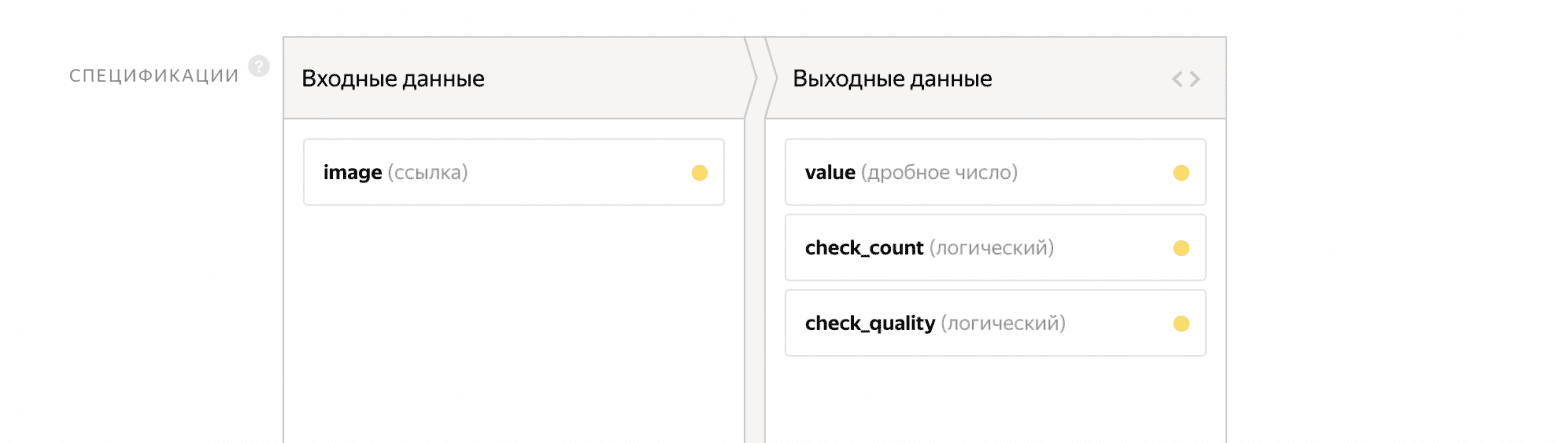
В качестве входных параметров передаем ссылку на изображение. На выходе будет два флага:
- check_count — ответ на первый вопрос
- check_quality — ответ на второй вопрос
В переменную value будут записываться показания счетчика.
Интерфейс этого задания занимает уже 14 строк.

Для повышения точности одно изображение будут проверять независимо друг от друга 5 толокеров, для этого поставим перекрытие 5. После этого мы будем смотреть как ответили 5 людей и считать, что верный вариант ответа тот, за который проголосовало большинство. Данное задание уже не будет иметь отложенную приемку.
Допустим к заданию 50% лучших исполнителей.
В заданиях без отложенной приемки выплату получают все, вне зависимости от того, выполняют они задание правильно или нет. Но мы же хотим, чтобы толокеры внимательно читали инструкцию, старались и выполняли задание верно. Каким образом можно этого добиться?
В Толоке есть два основных инструмента, которые позволяют поддерживать хорошее качество:
- Обучение. Перед выполнением основного задания мы можем попросить толокеров пройти обучение. В пуле обучения людям даются задания, на которые мы заранее знаем правильные ответы. В случае, если человек ответил неправильно, ему показывается ошибка и объясняется, как нужно было ответить. После прохождения обучения мы видим с каким процентом заданий исполнитель справился и можем допустить к основному пулу заданий только тех, кто справился хорошо.
- Блоки контроля качества. Может быть такая ситуация, что пул обучения исполнитель прошел на "отлично", мы его допустили к заданию, но через пять минут он ушел играть в футбол, оставив за компьютером своего трехлетнего брата. К счастью, в Толоке есть множество методов, которые позволяют следить за тем, как люди выполняют задания.
С пулом обучения все просто: достаточно добавить задания, разметить их в интерфейсе Яндекс. Толоки и указать порог прохождения, начиная с которого мы допускаем людей к основному заданию.

С блоками контроля качества все интереснее: их довольно много, но я остановлюсь на двух самых важных.
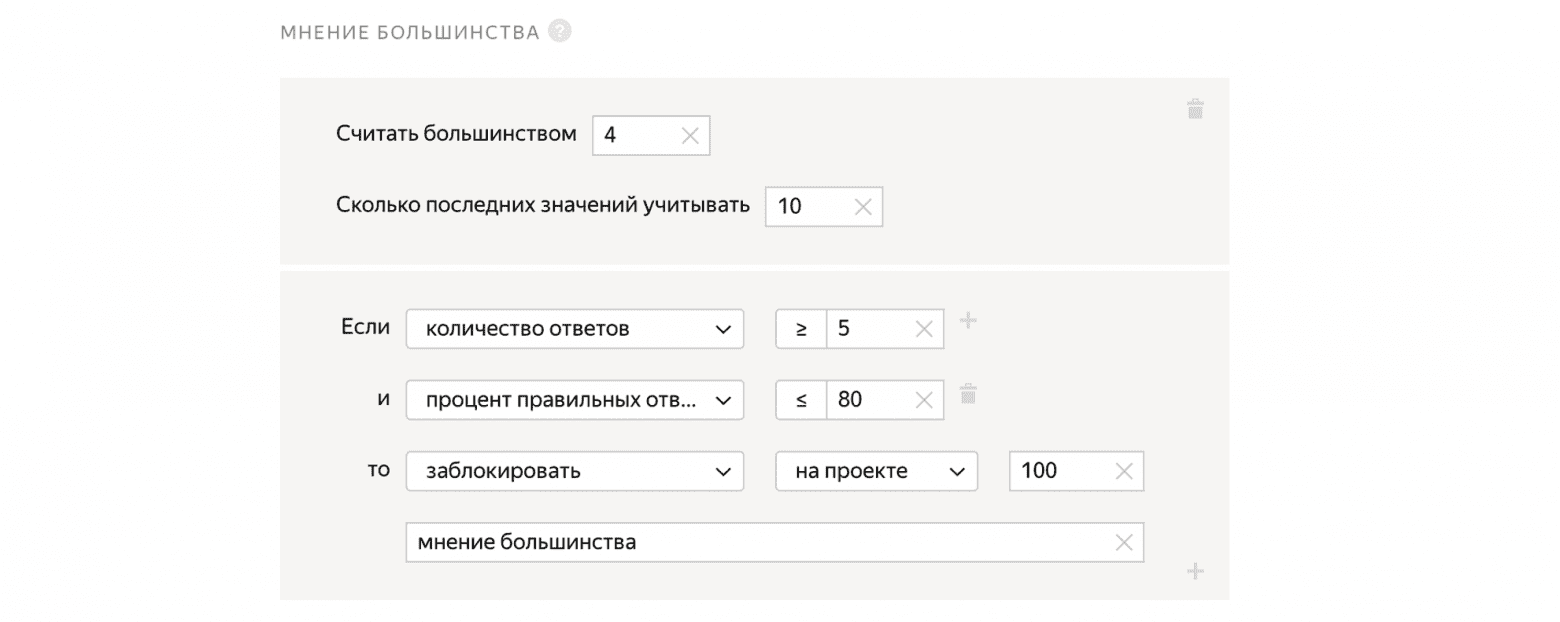
Мнение большинства
Мы даем задание 5-и независимым людям. И если четыре человека на вопрос отвечают "Да", а пятый отвечает "Нет", то пятый, вероятно, ошибся. Таким образом, мы можем смотреть, как ответы человека согласуются с ответами других людей, и блокировать пользователей, которые отвечают не так, как остальные.
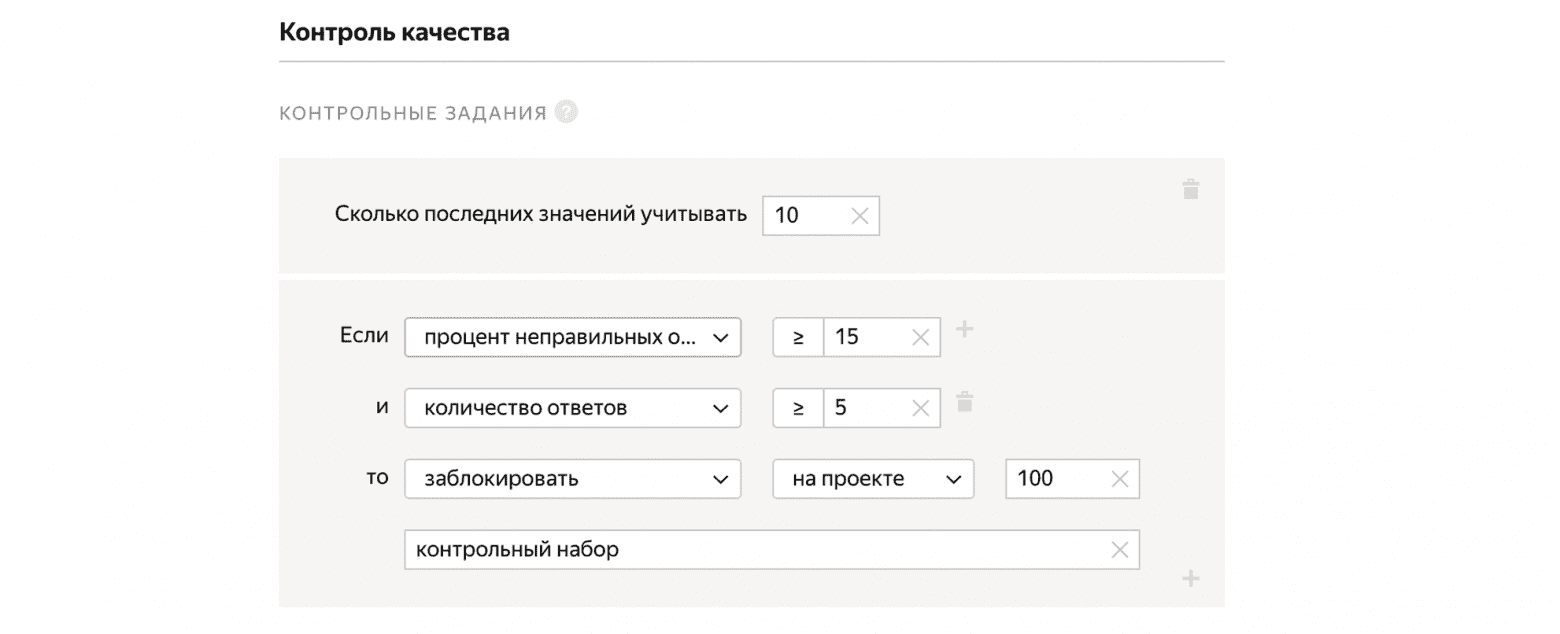
Контрольные задания
Мы можем подмешивать в пул задания, на которые заранее знаем верный ответ. При этом задания контроля качества выглядят так же, как и обычные задания. На основе того, правильно ли человек отвечает на контрольные задания, мы можем экстраполировать и предполагать, правильно или нет он решает все остальные задачи, для которых мы ответов не знаем. Если человек отвечает плохо на контрольные задания, мы можем его заблокировать, а если хорошо, то выдать бонус.
Ура, задание создано! Вот так выглядит интерфейс со стороны исполнителя:

Часть 3. Объединение заданий
Отлично, задания готовы! Но возникает вопрос, как соединить задания между собой? Как сделать так, чтобы после первого задания запускалось второе?
Конечно, можно пошаманить с бубном и сделать это вручную через интерфейс Толоки, но есть способ проще и быстрее! В Яндекс. Толоке есть API, воспользуемся им и напишем скрипт на питоне!
import pandas as pd
import numpy as np
import requests
import boto3
# Данная функция скачивает изображение из первого задания, загружает
# в Yandex Object Storage и возвращает ссылку на изображение
defload_image_on_yandex_storage(img_id):
session = boto3.session.Session (
region_name="us-east-1", aws_secret_access_key="", aws_access_key_id=""
)
s3 = session. client (
service_name="s3", endpoint_url="https://storage.yandexcloud.net"
)
file = requests. get (
url=URL_API + "attachments/%s/download" % img_id, headers=HEADERS
)
s3.put_object (Bucket="schetchiki", Key=img_id, Body=file.content)
return "https://storage.yandexcloud.net/schetchiki/%s" % img_id
# Указываем ключ к API, а также ID пула первого и второго задания
TOLOKA_OAUTH_TOKEN = ""
POOL_ID_FIRST = 7 156 932
POOL_ID_SECOND = 7 006 945
URL_API = "https://toloka.yandex.ru/api/v1/"
HEADERS = {
"Authorization": "OAuth %s" % TOLOKA_OAUTH_TOKEN,
"Content-Type": "application/JSON",
}
# Получаем список всех заданий из первого пула, которые ждут проверки
url_assignments = (
URL_API + "assignments/?status=SUBMITTED&limit=10 000&pool_id=%s" % POOL_ID_FIRST
)
submitted_tasks = requests. get (url_assignments, headers=HEADERS).json ()["items"]
# Заводим словари, чтобы помнить, как соотносятся id задания из первого пула
# и id задания из второго пула
url_to_first_id_map = {}
first_id_to_second_id_map = {}
json_second_task = []
# Для каждого задания из первого пула:
# * Запоминаем его id
# * Загружаем картинку в Yandex Object Storage
# * Оборачиваем параметры в json для второго задания
for task in submitted_tasks:
first_task_id = task["id"]
img_id = task["solutions"][0]["output_values"]["img"]
url_img = load_image_on_yandex_storage (img_id)
url_to_first_id_map[url_img] = first_task_id
json_second_task.append (
{"input_values": {"image": url_img}, "pool_id": POOL_ID_SECOND, "overlap": 5}
)
# Загружаем задания во второй пул
# "Не баг, а фича": добавлять через API задания в пул можно только тогда,
# когда сам пул создан через API
second_tasks_request = requests. post (
url=URL_API + "tasks?open_pool=true", headers=HEADERS, json=json_second_task
).json ()
# В ответ нам выдали id вторых заданий.
# По ним мы сможем запросить ответы после завершения задания, поэтому запомним их
for second_task in second_tasks_request["items"].values ():
second_task_id = second_task["id"]
img_url = second_task["input_values"]["image"]
first_task_id = url_to_first_id_map[img_url]
first_id_to_second_id_map[first_task_id] = second_task_id
# Эту функцию я писал ночью, утром я сам не смог понять, как она работает
# Она возращает ответы пользователей для конкретного поля
def unknown_fun(k):
return list (map (lambda t: t['solutions'][np.where (np.array (list (map (lambda x: x['id'], t['tasks']))) == second_task_id)[0][0]]['output_values'][k], second_task))
# Меняем keys и values местами
first_id_to_url_map = dict ((v, k) for k, v in url_to_first_id_map.items ())
db = []
# Выполняем этот код только после того, как задание 2 будет выполнено
for first_task_id in first_id_to_second_id_map:
# Для каждого проверяемого задания 1
second_task_id = first_id_to_second_id_map[first_task_id]
# Получаем результаты задания 2
url_assignments = (
URL_API + "assignments/?status=ACCEPTED&task_id=%s" % second_task_id
)
second_task = requests. get (url_assignments, headers=HEADERS).json ()["items"]
# Получаем вектор ответов пользователей
value_list = unknown_fun ("value")
check_count_list = unknown_fun ("check_count")
check_quality_list = unknown_fun ("check_quality")
# Если больше двух людей ответили на первый вопрос "нет",# то значит счетчика на изображении нет,# либо на изображении несколько счетчиков. Отклоняем задание
if np. sum (check_count_list) < 3:
json_check = {
"status": "REJECTED",
"public_comment": "На фотографии должен быть ровно один счетчик холодной либо горячей воды",
}
# Если больше двух людей сказали, что показания не видны, отклоняем задание
elif np. sum (check_quality_list) < 3:
json_check = {
"status": "REJECTED",
"public_comment": "Показания на счетчике отчетливо не видны",
}
# В остальных случаях принимаем задание
else:
json_check = {
"status": "ACCEPTED",
"public_comment": "Изображение счетчика принято",
}
url = URL_API + "assignments/%s" % first_task_id
result_patch_request = requests. patch (url, headers=HEADERS, json=json_check)
# Найдем для принятых заданий самый частый ответ
(values, counts) = np. unique (value_list, return_counts=True)
ind = np. argmax (counts)
if counts[ind] > 3and json_check["status"] == "ACCEPTED":
print (
"Показания счетчика: %s. Его подтвердили %d из 5 пользователей"
% (values[ind], counts[ind])
)
# Чтобы ничего не забыть и не потерять, записываем в массив
db.append (
{
"first_task_id": first_task_id,
"second_task_id": second_task_id,
"url_img": first_id_to_url_map[first_task_id],
"check_count_list": check_count_list,
"check_quality_list": check_quality_list,
"value_list": value_list,
}
)
# Сохраняем получившийся результат
pd.DataFrame (db).to_csv ("result.csv")
Запускаем код и вот долгожданный результат: датасет из 871 изображений счетчиков готов.

Цена
Давайте оценим экономическую составляющую проекта.
За присланное изображение в первом задании мы предлагаем 0.01 $.
К сожалению, если мы платим исполнителю 0.01 $, нам придется отдать 0.018 $.
Как это получается?
- Комиссия Яндекса равна min (0.005,20%). Для задания ценой 0.01 $ комиссия будет 50%;
- НДС составляет 20%.
За проверку 10 изображений счетчиков мы платим 0.01 $. При этом одно изображение проверяют 5 раз независимые люди. Итого, за проверку одного изображения мы отдаем: (0.01×5 / 10) x 1.2×1.5 = 0.009 $.
Из 1000 присланных заданий было принято 871 изображение, а 129 было отклонено. Значит, чтобы получить датасет из 871 изображений, мы заплатили:
0.018 $ x 871 + 0.009 $ x 1000 = 25 $ и для получения датасета в размере 50 000 изображений понадобится 92 000 руб. Это определенно дешевле, чем заказывать рекламу на федеральном канале!
Но и данную цифру реально уменьшить в несколько раз. Можно:
- Предлагать в первом задании делать не одно фото, а несколько. При этом поднять цену, тогда комиссия Яндекса будет не 50%, а 20%;
- Использовать динамическое перекрытие во втором задании. Если 4 из 5 людей дали одинаковый ответ, то уже не имеет смысла выдавать задание пятому человеку;
- Работать с Толокой как иностранное юридическое лицо. В этом случае вы не платите НДС.
Так как материала оказалось уж очень много, то мною было принято решение разбить статью на две части. В следующий раз мы поговорим с вами о том, как с помощью Толоки выделять объекты на изображениях и создавать датасеты для задач в области Computer Vision. А чтобы не пропустить, подписывайтесь и ставьте лайки!
P.S.
После прочтения статьи вам может показаться, что это скрытая реклама Яндекс. Толоки, но нет, это не так. Яндекс мне ничего не платил, да и, скорее всего, не заплатит. Я лишь хотел показать на выдуманном, но актуальном и интересном примере, как с помощью данного сервиса можно собрать быстро и недорого датасет под любую задачу, будь это задача распознавания котиков или обучения беспилотных автомобилей.