



В некоторых областях можно почти без проблем использовать данные с высокой частотой ошибок, в других же система даёт сбой при малейших погрешностях в большом датасете. Принцип «мусор на входе, мусор на выходе» нужно воспринимать со всей серьёзностью. Мельчайшая некорректность в наборах данных может иметь большое влияние на модель и приводить к созданию бесполезных результатов. Чистота и целостность данных — ключевой аспект в создании сложных моделей машинного обучения.

Огромная цена низкого качества данных
Гораздо экономнее предотвращать проблемы с данными, чем разрешать их. Если у компании есть 500 тысяч записей и 30% из них неточны, тогда на устранение этих проблем придётся потратить 15 миллионов долларов вместо 150 тысяч долларов, которые были бы потрачены на их предотвращение.
Big Data уже давно стала модным термином и многие компании убедили себя, что чем больше у них данных, тем большую ценность из них можно извлечь. Однако они не учитывают то, что для получения хорошего экономического эффекта данные нужно собрать, разметить и обработать.
Качество зависит от множества факторов
Важность качества данных зависит от текущего этапа производства. Когда вы только начинаете и пытаетесь создать впечатляющее доказательство работоспособности концепции (proof of concept, POC), самое главное — это сбор данных, при этом может потребоваться пожертвовать качеством. Однако после того, как продукт прошёл этап POC и критически важной стала надёжность, нужно отдать приоритет качеству в ущерб скорости.
Необходимый уровень качества зависит от области применения. При аннотировании автомобиля рамкой вполне приемлема погрешность в 3 пикселя. Однако при разметке ключевых точек лица сдвиг пикселей не допускается. Погрешность в 3 пикселя может сделать разметку лица бесполезной.
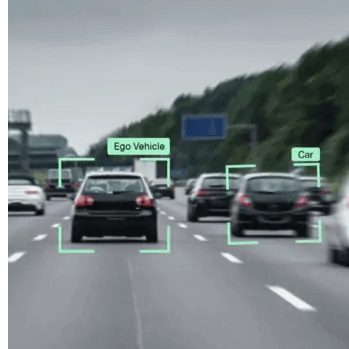
Также на качество могут влиять различные объекты на сцене. Например, в случае беспилотных автомобилей должна быть высокой точность выделения объектов рядом с тестируемым автомобилем, и находящихся с ним на одной полосе. Однако в случае далёких объектов и объектов, не находящихся на одной полосе, допускается снижение качества.
80% работы — это подготовка данных
Основатель deeplearning. ai и бывший руководитель Google Brain Эндрю Ын говорит: «во многих задачах полезно было бы изменить свою точку зрения, чтобы не только совершенствовать код, но и более системным образом совершенствовать данные».
Ын считает, что развитие машинного обучения можно ускорить, если процесс станет ориентироваться на обработку данных, а не на создание моделей. В основе традиционного ПО лежит код, а системы ИИ создаются из данных и кода, принимающего форму моделей и алгоритмов. «Когда производительность системы низка, многие команды инстинктивно стремятся улучшить код. Но во многих практических сферах применения эффективнее сосредоточиться на совершенствовании данных», — говорит Ын. Считается, что 80% машинного обучения — это очистка данных. «Если 80% нашей работы — это подготовка данных, почему мы не думаем, что обеспечение качества данных — самое важное для команды, занимающейся машинным обучением?»

Целостность — ключ к качеству данных
Для разметки данных «главное — это целостность», и особенно важна она при разработке ИИ. При разметке наборов данных метки должны быть одинаковыми во всех системах разметки и пакетах данных.
Ошибки возникают очень часто, потому что разные люди могут интерпретировать руководство по разметке данных по-разному, из-за чего набор данных становится шумным и противоречивым.
Работайте систематично и на всём протяжении жизненного цикла машинного обучения используйте проверенные инструменты и процессы. На этапе обучения модели критически важен структурированный анализ ошибок.
Разметка данных с упором на качество
В одном из случаев фоновый шум автомобиля помешал обучению алгоритма распознавания речи. При ориентировании на данные разработчики выявили бы ошибку (шум автомобиля), а затем обучили бы модель на большем объёме данных, в том числе и с шумами автомобилей. Это должно повысить целостность разметки, данные были бы помечены как что-то вроде «речи с шумным фоном, содержащим шум автомобиля».
Хотя это может показаться контринтуитивным, даже данные с раздражающим фоновым шумом автомобиля становятся качественно размеченными данными, которые, в свою очередь, становятся качественными данными для обучения.
После правильной разметки «фонового шума автомобилей» в наборе данных для машинного обучения модели алгоритм распознавания речи должен научиться понимать шум автомобиля и отличать его от речи, которую ему нужно распознавать.
Инструменты разметки данных не гарантируют качества
Нельзя недооценивать важность правильной разметки данных. Естественно, это наводит на вопрос: «Какой инструмент обработки данных подходит для моей области применения?«
Сервисы разметки данных применяются для сложных алгоритмов машинного обучения, компьютерного зрения, обработки естественных языков, дополненной реальности и аналитики данных. Компании используют свои передовые технологии в онкологических исследованиях, обучении беспилотных автомобилей и оптимизации урожайности посевов.
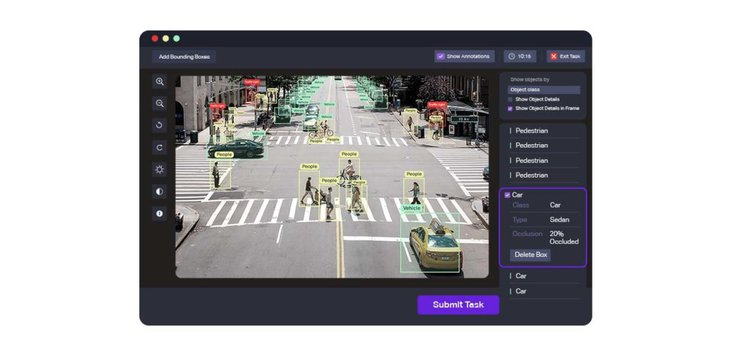
Cуществует широкий выбор инструментов разметки данных, специализирующихся на различных областях использования, например, Lionbridge AI, Amazon Mechanical Turk (MTurk), Computer Vision Annotation Tool, SuperAnnotate, LightTag, DataTurks, Playment и Tagtog. Некоторые из них бесплатны, за большинство нужно платить. Некоторые лучше работают с видео, или с изображениями, или с данными лидаров.
MTurk — это краудсорсинговая площадка для разметки данных. MTurk — одно из самых дешёвых решений на рынке, но он имеет множество недостатков, в том числе отсутствие ключевых функций контроля качества. Он предоставляет очень мало возможностей обеспечения качества, тестирования работы сотрудников и подробной отчётности. Более того, тяжёлая нагрузка по управлению проектом возлагается на заказчика, требуя от него нанимать сотрудников, а также отслеживать все задачи.
Computer Vision Annotation Tool (CVAT) может похвастаться широким набором функций для разметки данных компьютерного зрения; он поддерживает такие задачи, как распознавание объектов, сегментация изображений и классификация изображений. Однако его интерфейс пользователя сложен и требует долгого освоения.
SuperAnnotate можно использовать для классификации данных изображений, видео, лидаров, текста и звука. В его расширенные функции входят автоматическое прогнозирование, трансферное обучение, инструменты управления данными и качеством. Компания утверждает, что производительность её продукта в три раза выше, чем у конкурентов.
LightTag работает только с текстовыми данными, но имеет бесплатную начальную версию. Ещё одна open-source-платформа DataTurks предоставляет сервисы для разметки текстовых, графических и видеоданных. Playment работает с изображениями и полезен для создания наборов данных для обучения моделей компьютерного зрения. Ещё один инструмент разметки текста — Tagtog может аннотировать данные и автоматически, и вручную.
Тренды разметки данных
ИИ скоро совершит революцию во множестве различных отраслей, но самым важным аспектом является разметка данных. Например, при правильной разметке снимков компьютерной томографии ИИ сможет обнаруживать в снимках КТ грудной клетки пневмонию, вызванную COVID-19.
В качестве других примеров можно привести распознавание голов людей, выявление поведения толпы на камерах видеонаблюдения для мониторинга безопасности, ликвидацию аварий и мониторинг дорожного движения. Обработка естественных языков может использоваться для распознавания сущностей, атрибутов, а также определения взаимосвязей между факторами, помогающими совершенствовать разработку лекарств.
Строительство, железнодорожные перевозки и энергетическая отрасль могут выиграть от аннотирования записанных дронами данных лидаров. Роботизированная автоматизация процессов (Robotic Process Automation, RPA) может ускорить процесс бухгалтерского учёта, обеспечив при этом отсутствие ошибок.
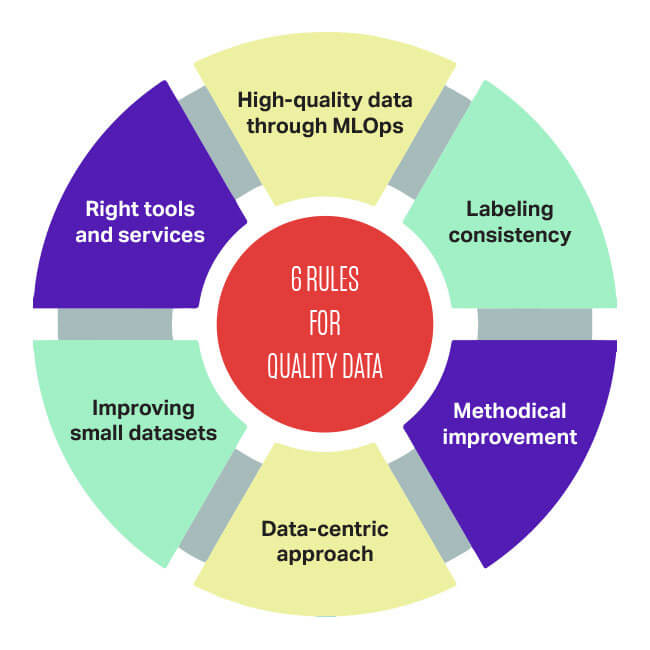
6 правил обеспечения качества данных
Для эффективной реализации машинного обучения следуйте этим шести простым правилам обеспечения качества данных:
- При работе с MLOps важнее всего обеспечить высокое качество данных.
- Обязательна целостность данных.
- Методичное совершенствование качества данных простой модели часто лучше, чем реализация современной модели на основе низкокачественных данных.
- Следует всегда ориентироваться в первую очередь на данные.
- Если вы в первую очередь ориентируетесь на данные, то существует большой потенциал для совершенствования, когда задачи содержат наборы данных небольшого размера (допустим, меньше 10 тысяч).
- При использовании небольших наборов данных критически важны инструменты и сервисы, повышающие качество данных.
Хорошие данные обладают целостностью, покрывают все пограничные случаи, имеют своевременную обратную связь с данными в продакшене и обладают нужным объёмом. Вместо того, чтобы рассчитывать на инженеров, наудачу исправляющих модель, гораздо более важной целью любой команды MLOps является обеспечение высококачественного и целостного потока данных между всеми этапами проекта машинного обучения.
«Качество данных требует определённого уровня компетентности, она требуется даже для понимания того, в чём заключена проблема», — рассказывает основатель и CEO NextGen compliance Колин Грэм.
ИИ может быть сложной в реализации технологией и передача плохих или некачественно размеченных данных почти всегда гарантирует провал. Достичь уровня, при котором качество данных контролируется в рамках стандартной эксплуатации — это не просто цель, это необходимость.