



Распознавание сущностей (NER, Named Entity Recognition) — это часть обработки естественного языка (NLP), область искусственного интеллекта. НЛП занимается компьютерной обработкой и анализом естественного языка, т. е. любого, который развился естественным образом, а не был создан специально, как, например, языки программирования. Если проще, NLP обучает компьютер понимать устную речь и текст на уровне человека.
Обработка естественного языка состоит из трех этапов:
- Синтаксис — структура и правила речи.
- Семантика — значение слов и выражений, распознавание взаимосвязей и логических цепочек в тексте.
- Речь — способность воспринимать слова и предложения на слух и преобразовывать их в текст.
NER используется в семантическом этапе: считывает и понимает значение написанных слов и разносит их по классам.
Что такое именованные сущности?
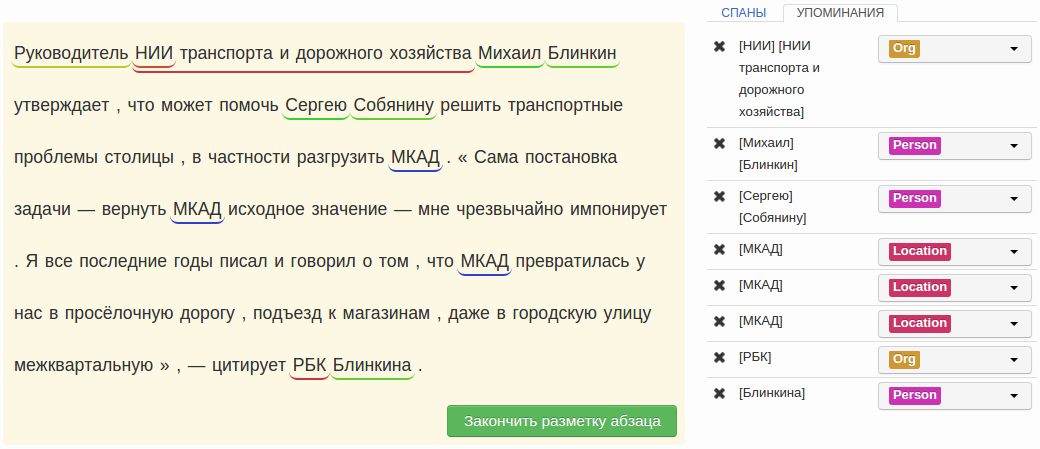
Это слова и выражения, обозначающие имена людей, названия организаций, даты, числа и т. д., в текстовых данных. Наиболее важные фрагменты конкретного предложения, то, о чем идет речь.
Например:
Свадьба принца Гарри, герцога Сассекского, и Меган Маркл состоялась 19 мая 2018 года.
В этом предложении можно выделить именованные сущности:
- Person (Человек) — принц Гарри, герцог Сассекский, Меган Маркл.
- Date (Дата) — 19 мая 2018 года.
- Event (Событие) — свадьба.
Типичная модель NER состоит из следующих шагов:
- Токенизация — текст разбивается на отдельные токены, обычно слова и знаки препинания.
- Маркировка частей речи — существительное, глагол, прилагательное и т. д.
- Группировка — токены группируются на основе маркировки части речи.
- Распознавание именованных сущностей, их маркировка и классификация («человек», «животное», «дата»).
- Устранение неоднозначности — нужно определить, о какой именно Меган идет речь в тексте.
В результате модель машинного обучения NER будет автоматически сканировать целые статьи, находить известные ей слова и правильно их классифицировать по заранее определенным категориям для понимания текста или извлечения важной информации при формировании баз данных.
Где используется распознавание сущностей?
Проблемы распознавания сущностей
При использовании NER вы получаете максимально точную и честную выборку по заданному сценарию без учета человеческого фактора. Технология подходит практически для всех отраслей бизнеса, освобождает сотрудникам время на другие задачи. Возможные проблемы возникают только при недостаточном/неполном обучении модели. Среди них, например, сложности с определением лексической двусмысленности: так, в предложении «Малыш сел на кресло и сломал ручку» без дополнительного контекста не понять, что именно сломал ребенок, ручку кресла или свою руку. Также часто модель не знает значения иностранных слов, путается в правописании и т. д. Для хорошего результата нужен большой объем обучающих данных, правильно подобранных и размеченных.
Как начать работать с NER?
Существует ряд библиотек с открытым исходным кодом, например, NLTK. В ней есть инструменты и ресурсы для работы с текстовыми данными, а также готовые модели обработки языка для обучения. Можно скачать и использовать в своих проектах на языке программирования Python. Но, прежде чем начать построение модели, вам нужен соответствующий датасет для ее обучения.
Команда Training Data Solutions подготовит компьютерный или рукописный текст по вашим сущностям и категориям на 30+ языках. Сделаем разметку, структурируем и классифицируем, вернем в виде набора обучающих данных для модели NER. Тестовый датасет пришлем бесплатно, оставьте ваши данные в форме.