


Аннотация — процесс разметки данных соответствующими тегами (характеристиками, признаками, атрибутами), по которым ИИ учится определять или «видеть», что именно перед ним находится. Данные могут быть в виде изображений, текста, аудио или видео. Их разметка выполняется вручную человеком, полуавтоматически в инструментах разметки или полностью автоматически с помощью нейросетей.
На правильно аннотированных данных модель может, например:
- Классифицировать — распределять полученную информацию по категориям. Например, анализировать результаты УЗИ и определять наличие или отсутствие заболеваний.
- Работать по методу регрессии — находить взаимосвязь между зависимой и независимыми переменными. Например, оценивать, как связаны выделенный на рекламу бюджет и количество продаж товара
Почему аннотация данных так важна?
Мы не задумываемся, какую работу делает мозг, чтобы узнать предмет и отнести его к определенному классу. Это занимает доли секунды: передо мной тополь, персидская кошка, друг Гена. Чтобы ИИ мог делать то же самое, его нужно обучить.
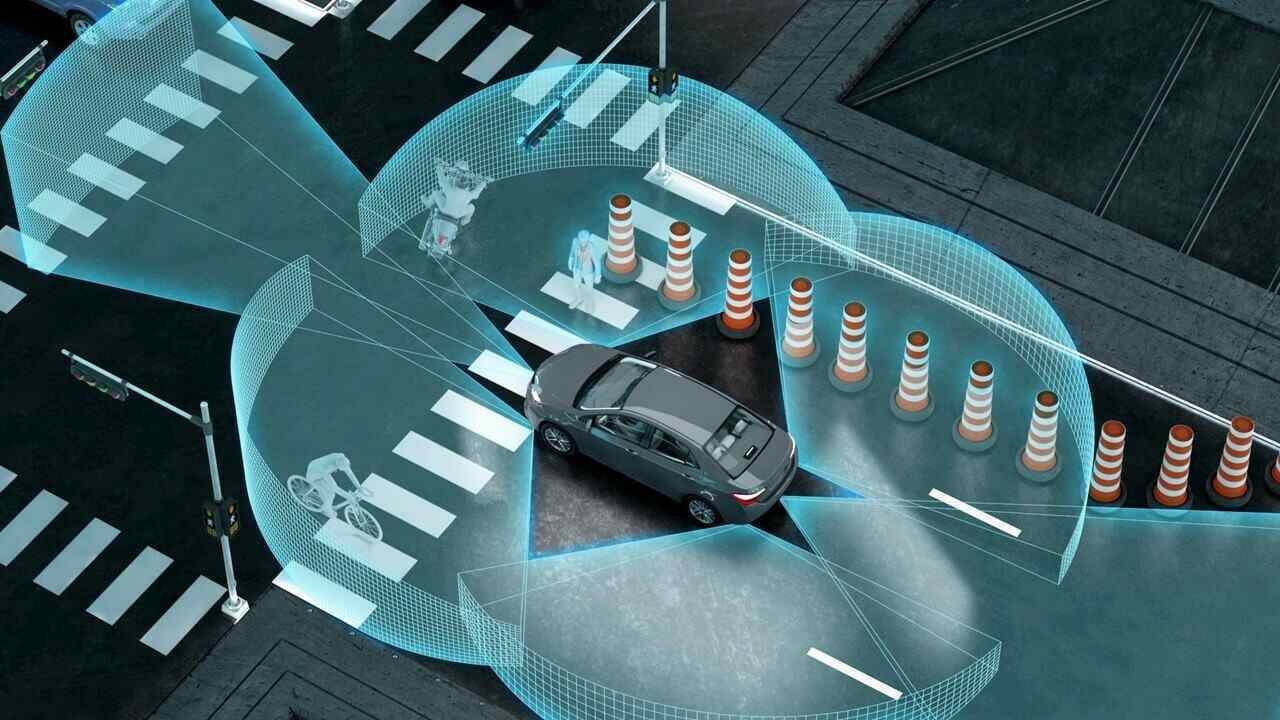
Представьте себе беспилотный автомобиль. Он двигается, опираясь на данные компьютерного зрения, датчиков и обработки естественного языка NLP. Чтобы понимать, что перед ним: пешеход, дорожная разметка, другой автомобиль или экипаж ДПС, — он должен получить полный объем размеченных и «подписанных» данных. В упрощенном виде это может быть датасет изображений с тегами «кошка», «собака», «человек», «тротуар» и т. д. Без аннотаций, просто по картинке, машина не отличит собаку от дорожного знака.
Высококачественная аннотация данных — одна из основных задач для точных моделей машинного обучения. Так, по оценкам исследовательской компании Cognilytica, на подготовку датасета уходит до 80 % времени разработки ИИ-проекта. Малейшая ошибка в моделях AI/ML может нанести катастрофический вред здоровью и жизни человека — например, в здравоохранении, если, конечно, доверять ей на 100%, чего пока человечество не может себе позволить.

Типы аннотации данных:
- Текстовые — выполняются для виртуальных помощников, чат-ботов с искусственным интеллектом (например, ChatGPT). Позволяют ИИ давать разумные ответы на вопросы, поддерживать диалог максимально близко к естественной речи. В текстовую аннотацию добавляют метаданные, чтобы компьютер «видел» ключевые слова и использовал их при принятии решений.
- Видео — чтобы ИИ мог распознавать движущиеся объекты с помощью компьютерного зрения. Данные используются, например, в датасетах для машинного обучения беспилотных автомобилей.
- Изображения — самый важный процесс аннотации данных для создания ИИ. Цель: научить AI модели узнавать объекты на картинках.
Как происходит аннотация данных?
С помощью инструментов для аннотации эксперты размечают наборы данных всех типов. Под инструментами подразумеваются локальные или облачные решения (платформы) с широким набором функций. Мы используем различные инструменты в зависимости от задачи, один из них — Label Studio. Он представлен в опенсорсной и Enterprise-версии. Опенсорсная поддерживает большинство видов аннотации (классификацию изображений, распознавание объектов, семантическую сегментацию и т. д.). Конфигурация Labeling Config позволяет проектировать свой UI. Здесь есть много автоматических функций, например предварительная разметка на основе модели машинного обучения.
Рассмотрим процесс аннотации для разных данных.

Аннотация изображений
Для машинного обучения к изображениям добавляют подписи, идентификаторы и ключевые слова в качестве атрибутов. Виды:
- классификация — назначение категорий или меток на основе содержимого. Используется для автоматического распознавания и сортировки изображений по классам. Например, мужчина это или женщина;
- распознавание/обнаружение — идентификация и маркировка конкретных объектов на изображении. В отличие от классификации, здесь задача ИИ — найти и определить заданный предмет, существо или человека. Например, Face ID в iPhone «запоминает» объемный снимок лица пользователя, а при последующих проверках сравнивает новые изображения с исходным и производит идентификацию;
- семантическая сегментация — попиксельное разделение изображения на сегменты или области, где каждому пикселю присваивается класс. Например, на натюрморте с фруктами и ягодами используются классы «апельсин», «клубника», «киви», а также класс «фон». Это сверхточная аннотация данных.
Аннотация звуковых данных
При аннотации аудиоданных используется больше параметров, чем для изображений. Для правильного обучения модели в зависимости от задачи указывают язык записи, диалект, эмоции, адрес диктора и т. д. Кроме словесных сигналов размечаются также фоновый шум, тишина, дыхание. На таких данных, например, обучается голосовой помощник Алиса.
Аннотация видео
Видео — это набор последовательных изображений (кадров). При видеоаннотации ключевые точки, линии и окружности для выделения объектов отображаются на каждом кадре. Когда изображения объединяются, модели ИИ могут изучать движения, поведение, шаблоны и т. д. В основном такие данные используются для обучения автономного транспорта.
Аннотация текста
Текст — это отзывы клиентов, упоминания в социальных сетях, обзоры и многое другое. И это огромный источник ценной информации для бренда. Человек поймет контекст фразы, заметит сарказм и юмор. Теперь этому нужно научить ИИ.
Виды аннотации текстовых данных:
- семантическая — значение и связи между словами и предложениями. Хороший чат-бот очень реалистично имитирует человеческий разговор;
- намерения — для чего этот текст? Специалист назначает метки абзацам, где видны интенции пользователя: запрос, поиск дополнительной информации, рекомендация;
- настроения — модель машинного обучения на основании расставленных тегов учится различать эмоциональную окраску текста;
- объекта — распознавание и маркировка частей речи, тегирование ключевых фраз, конкретных названий (например, известных персон, брендов, организаций).
Этапы аннотации данных:
- Сбор информации: изображений, видео, аудио или текстов с заданными параметрами.
- Предварительная обработка — стандартизация, форматирование, подготовка к аннотации.
- Выбор инструмента или исполнителя в зависимости от требований проекта.
- Подготовка технического задания.
- Сама маркировка и разметка данных.
- Проверка качества результатов.
- Экспорт в требуемый формат.
Весь процесс аннотации данных может занять от нескольких дней до нескольких недель. Всё зависит от объема проекта, сложности и доступных ресурсов.
Наша команда выполняет все виды аннотации данных для машинного обучения: от сбора информации до передачи клиенту в нужном читаемом формате. Оставьте заявку — подготовим тестовый датасет для вашей задачи бесплатно. Закрываем 90 % проектов раньше срока.
Наша команда выполняет все виды аннотации данных для машинного обучения: от сбора информации до передачи клиенту в нужном читаемом формате. Оставьте заявку — подготовим тестовый датасет для вашей задачи бесплатно. Закрываем 90 % проектов раньше срока.