



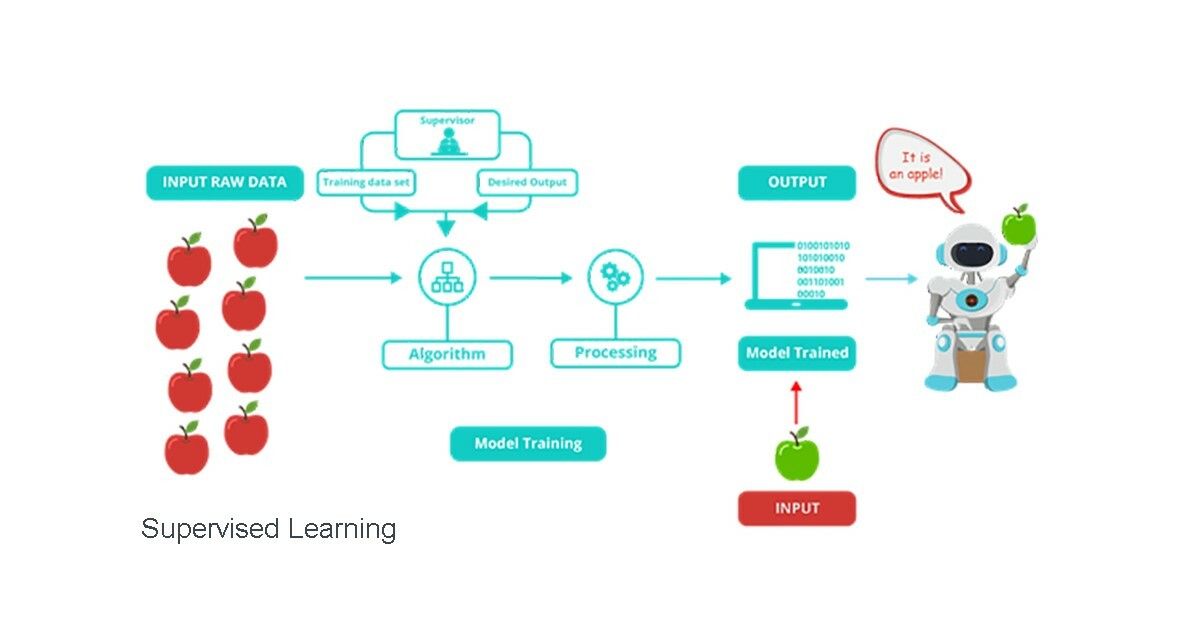
Тренировочные или обучающие данные (Training Data) используются в машинном обучении в связке с проверочными (Validation Data) и тестовыми (Testing Data). На их основе модель учится обрабатывать информацию. ИИ имитирует способность человеческого мозга принимать входные данные и «взвешивать» их, оценивать, чтобы потом принять решение. Большая часть этого процесса воспроизводится с помощью программ машинного обучения и нейронных сетей.
Например, если вы разрабатываете чат-бота для общения с клиентами, набор тренировочных данных может быть в виде текста или аудио. Для модели беспилотного автомобиля это изображения и видео с пешеходами, дорожными знаками и разметкой. Для медицинских исследований — результаты УЗИ, КТ, МРТ, снимки новообразований кожи и т. д.
Например, если вы разрабатываете чат-бота для общения с клиентами, набор тренировочных данных может быть в виде текста или аудио. Для модели беспилотного автомобиля это изображения и видео с пешеходами, дорожными знаками и разметкой. Для медицинских исследований — результаты УЗИ, КТ, МРТ, снимки новообразований кожи и т. д.
Виды тренировочных данных:
- Текст — научите ИИ считывать сарказм и иронию в тексте, определять его эмоциональную окраску, цель написания. Данные собираются, размечаются и проверяются на разных языках.
- Изображения — добавьте компьютерное зрение к возможностям вашей модели машинного обучения. ИИ научится определять и классифицировать объекты на картинке, идентифицировать лица и т. д.
- Аудио — создавайте интерфейсы, понимающие речь человека вне зависимости от языка и диалекта.
- Видео — научите модель «видеть» в реальном времени, обнаруживать объекты и принимать решения на ходу.
- Данные с датчиков — сделайте компьютерное зрение еще более совершенным с помощью аннотации облаков точек.
В более широком смысле тренировочные данные можно разделить на две категории: размеченные и неразмеченные.
Размеченные данные
Разметка, или аннотация, означает проставление меток, тегов, в которых прописаны характеристики, свойства и принадлежность объекта к определенному классу. Например, на фотографии фруктов можно прописать «апельсин», «банан», «персик». Это позволяет модели запомнить особенности объектов и определять их на новых наборах данных самостоятельно.
Сбор и разметка данных — долгий процесс. Несмотря на наличие платформ с автоматическими функциями, основная работа все равно выполняется вручную.
Неразмеченные данные
Это просто набор фотографий, видео или аудио без каких-либо меток. Используется в неконтролируемом машинном обучении, когда модель должна сама находить закономерности и паттерны без контроля пользователя. Если взять тот же пример с бананами и апельсинами, в неразмеченных данных никаких подписей не будет. Модель проанализирует каждое изображение, определит цвет, форму и сможет идентифицировать в дальнейшем. Конечно, она не будет знать, что перед ней именно апельсин, — но легко найдет его среди других фруктов.
Возможны гибридные модели, где используется контролируемое и неконтролируемое машинное обучение.
Где и как собирают тренировочные данные?
Необработанные данные можно получить от IoT-устройств, из соцсетей, с других сайтов, из отзывов клиентов, взять на открытых платформах машинного обучения, создать самостоятельно. После сбора информации нужно определить главные атрибуты, по которым модель сможет выдать результат.
Данные стандартизируют, очищают, размечают, конвертируют в нужный формат и загружают для машинного обучения.
Тренировочные данные низкого качества влияют на точность моделей, что может привести к потерям, причем не только финансовым. Представьте себе, что студент-хирург учится на тряпичной кукле. Справится ли он с операцией? А ведь ИИ сейчас активно используется для диагностики заболеваний.
Какими должны быть хорошие тренировочные данные?
- Соответствующими — датасет готовится строго под конкретную задачу.
- Разнообразными — например, если модель нужна для распознавания лиц, в пакете должны быть лица людей разных национальностей.
- Стандартизированными — данные из одного источника с одними атрибутами. Например, если вы анализируете данные клиентов, по каждому должны быть одинаковые сведения: ФИО, возраст, пол, количество заказов и т. д.
- Максимально полными — если это подборка для анти-спуфинга, нужны не только селфи людей, но и съемка распечатанных фотографий, грим, латексные маски и многое другое.
Что влияет на качество тренировочных данных?
Для моделей машинного обучения Training data — единственная книга, которую они читают. И единственный источник информации о мире. Их эффективность зависит от того, насколько подробной, точной и актуальной будет эта книга.
Качество данных зависит от трех факторов:

Как тренировочные данные используются в машинном обучении?
Готовый и размеченный набор данных можно использовать для обучения нейронных сетей. Перед началом отбираются проверочные данные — это выборка 10–20 % от основного датасета. На них модель будет периодически проверять себя при обучении.
Предположим, вы обучаете нейронную сеть беспилотного автомобиля. После обработки изображений других автомобилей модель выделит их основные признаки: колеса, размеры, зеркала заднего вида и т. д. И даже если в датасете преимущественно иномарки, а в тестовом наборе попадется «Лада», ИИ узнает ее и отнесет к тому же классу.
Тестирование — окончательный этап машинного обучения. Для него формируются специальные наборы данных, более конкретные. В том же примере с беспилотным транспортом в тренировочных данных могут быть изображения и видео дорожного движения на разных трассах в разное время года. Тестовый датасет можно составить только из съемок в темное время суток, в снежную бурю или с грязной камерой — чтобы убедиться, что автомобиль справится с задачей даже в сложных условиях.
Ни один учебник нельзя назвать полностью завершенным. Постоянно появляется новая информация, поэтому и для алгоритмов ML обучающая выборка должна периодически обновляться.
Нужно ли добавить в Training data все возможные примеры? Нет, как минимум, потому что это невозможно. Но если собрать достаточно полный датасет, ИИ далее будет обучаться самостоятельно, дополняя свои библиотеки информацией извне. Условно говоря, если в тренировочном наборе были только красные автомобили, а на тестировании модель видит синюю, она причислит ее к классу автомобилей по совокупности признаков и запомнит, что они бывают и красными.
Можно ли использовать опенсорсные датасеты?
Бесплатные наборы данных из открытых источников (Kaggle, Google Dataset Search и пр.) подходят для работы. Но вам, скорее всего, нужно будет настраивать их или повторно аннотировать. Мы составляем датасеты с помощью парсинга и веб-скрапинга, проводим работы на международных краудсорсинговых платформах, создаем синтетические данные по заданным параметрам и подбираем и чистим датасеты из открытых источников по техническому заданию. Оставьте заявку и мы отправим тестовый датасет по Вашему проекту бесплатно.