



В этом посте мы подробно рассмотрим процессы ETL и ELT, а также сравним их по важным критериям, чтобы вы могли понять, какой лучше подходит для вашего конвейера данных.
Краткое описание ETL и ELT
Как говорилось выше, ETL и ELT — это два способа интеграции данных в одно хранилище. Основное различие между ними заключается в том, ГДЕ и КОГДА выполняются преобразование и загрузка данных. При ETL данные преобразуются на временном этапе подготовки до того, как попадут в целевой репозиторий (например, в корпоративное хранилище данных), в то время как ELT позволяет преобразовывать данные после их загрузки в целевую систему (облачные хранилища данных или озёра данных). Почему это так важно? Давайте разбираться.
Что такое ETL?
ETL — это сокращение от extraction, transformation и loading. Это процесс сбора «сырых» данных из раздельных источников, передачи в промежуточную базу данных для преобразования и загрузки подготовленных данных в единую целевую систему.
Инструменты ETL используются для интеграции данных, чтобы удовлетворить требованиям систем управления реляционными базами данных и/или традиционных хранилищ данных с поддержкой OLAP (online analytical processing, аналитической онлайн-обработки). Инструменты OLAP и запросы (SQL) требуют, чтобы массивы данных структурировались и стандартизировались при помощи серии преобразований, выполняемых до того, как данные попадут в хранилище.
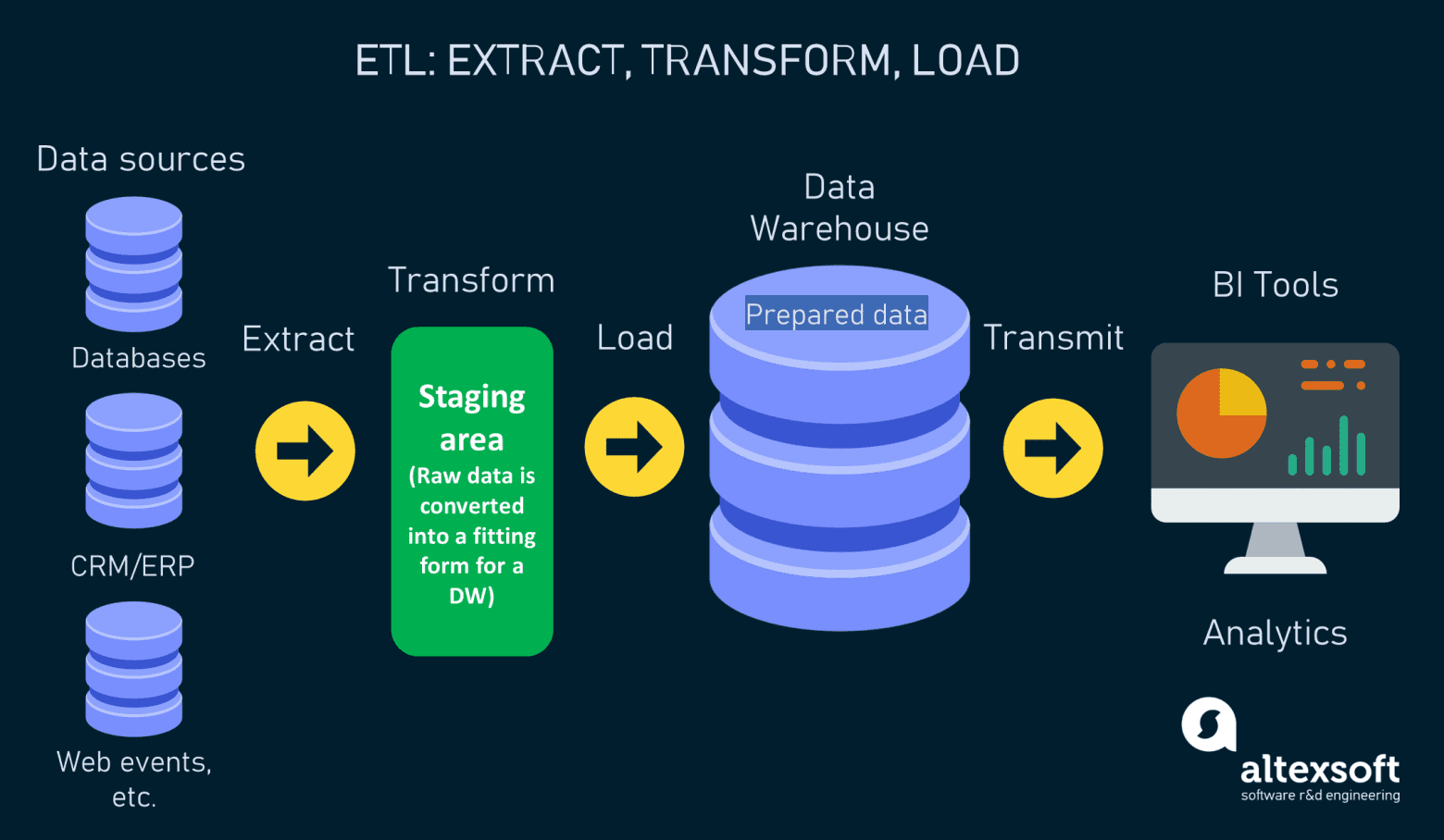
Эта методика возникла в 1970-х, когда компании начали использовать множественные репозитории данных для работы с разными типами бизнес-информации. С ростом объёмов разрозненных баз данных росла и потребность консолидации всех этих данных в централизованную систему. ETL возник как решение этой проблемы и стал стандартным методом интеграции данных. С конца 1980-х, когда появились хранилища данных, и до середины 2000-х ETL был основным способом создания баз данных, используемых как основа для бизнес-аналитики (business intelligence, BI).
С дальнейшим ростом объёмов и типов данных ETL становился не только довольно неэффективным, но более дорогостоящим и времязатратным. И тут на помощь пришёл ELT.
Что такое ELT?
Благодаря взрывному росту количества источников данных и всё усиливающейся потребности обработки огромных массивов данных для целей бизнес-аналитики и аналитики big data стала возрастать популярность ELT — альтернативы традиционному методу интеграции данных.
ELT — это сокращение от extraction, loading и transformation. По сути, ELT меняет местами два последних этапа процесса ETL, то есть после извлечения из баз данных данные загружаются напрямую в центральный репозиторий, где происходят все преобразования. Промежуточная база данных отсутствует.
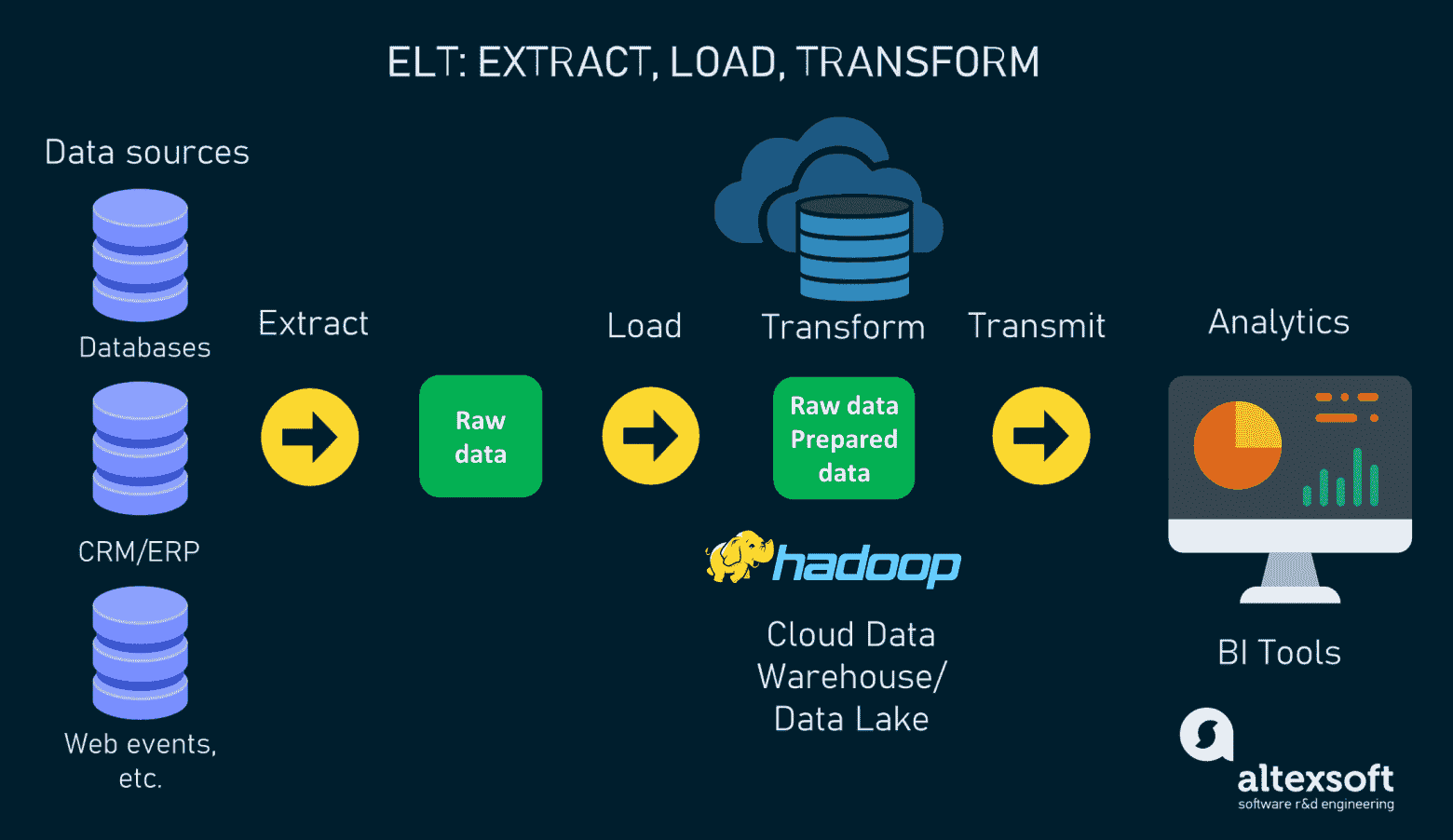
Такая методика стала возможной благодаря современным технологиям, позволяющим хранить и обрабатывать огромные объёмы данных в любом формате. В том числе и благодаря Apache Hadoop — опенсорсному ПО, которое изначально создавалось для непрерывного получения данных из различных источников вне зависимости от их типа. Облачные хранилища данных наподобие Snowflake, Redshift и BigQuery также поддерживают ELT, поскольку они разделяют ресурсы хранения и вычислений, а также обладают высокой масштабируемостью.
Ключевые этапы процессов ETL и ELT
Поток данных и в ETL, и в ELT использует три базовых этапа. Несмотря на одинаковое название, каждый из этапов этих методик отличается не только по порядку их выполнения, но и по тому, как они выполняются.
Извлечение (Extract)
Первый этап в обоих процессах
Путешествие данных всегда начинается с их извлечения и копирования из пула источников — систем ERP и CRM, баз данных SQL и NoSQL, приложений SaaS, веб-страниц, неструктурированных файлов, электронных писем, мобильных приложений и так далее. Из-за сложностей каждой из систем-источников первая фаза может быть довольно замысловатой.
Данные обычно извлекаются одним из трёх способов.
- Полное извлечение применяется к системам, которые не могут отличать новые или изменённые записи. В таких случаях единственным способом получения данных из системы является извлечение всех записей, как старых, так и новых.
- Частичное извлечение с уведомлениями об обновлениях — самый удобный способ извлечения данных из систем-источников. Он возможен, если в системах есть уведомления об изменениях записей, благодаря чему отсутствует необходимость загрузки всех данных.
- Инкрементное извлечение или частичное извлечение без уведомлений об обновлениях — это способ извлечения только тех записей, которые были изменены.
При использовании метода ETL пользователям нужно заранее планировать, какие элементы данных необходимо извлекать для дальнейшего преобразования и загрузки. С другой стороны, ELT позволяет извлекать все данные мгновенно. Пользователи могут позже решить, какие данные нужно преобразовывать и анализировать.
Преобразование (Transform)
Второй этап в ETL / третий этап в ELT
В фазу преобразования входит последовательность действий, нацеленных на подготовку данных для изменения их под параметры другой системы или для достижения нужного результата.
Преобразования могут включать в себя следующие действия:
- Сортировку и фильтрацию данных для избавления от нерелевантных элементов
- Устранение дубликатов и очистку
- Транслирование и преобразование
- Удаление или шифрование для защиты уязвимой информации
- Соединение или разделение таблиц и так далее
В ETL все эти операции происходят вне целевой системы, на этапе подготовки. За реализацию этих процессов отвечают дата-инженеры. Например, хранилища данных Online Analytical Processing (OLAP) допускают хранение только реляционных структур данных, поэтому данные предварительно должны преобразовываться в SQL-читаемый формат. Все преобразования могут происходить только один раз, из-за чего ETL оказывается довольно негибким. В случае, если необходимо применить к уже преобразованным данным новый тип анализа, то может потребоваться модификация всего конвейера данных с нуля.
Метод ELT гибок и удобен для преобразований, поскольку данные передаются напрямую в хранилище данных, озеро данных или data lakehouse, где они могут валидироваться, структурироваться и преобразовываться различным образом и в любой момент. Более того, «сырые» данные могут подвергаться бесчисленным преобразованиям, поскольку они хранятся неограниченно. Так как всё происходит внутри целевой системы, аналитики данных могут помогать дата-инженерам в выполнении преобразований, используя для этой цели SQL.
Загрузка (Load)
Второй этап в ELT/третий этап в ETL
Этот этап заключается в загрузке данных в целевую систему хранения данных, чтобы к ним могли получать доступ пользователи. Поток процесса ETL подразумевает импорт ранее извлечённых и уже подготовленных данных из промежуточной базы данных в целевое хранилище данных или базу данных. Это выполняется или путём физической вставки отдельных записей в качестве новых строк таблицы хранилища при помощи команд SQL, или с помощью сценария пакетной загрузки большого объёма данных.
ELT, в свою очередь, направляет массив «сырых» данных непосредственно в целевое место хранения, минуя промежуточный уровень. Это сильно экономит время цикла «извлечение-доставка». Как и в случае с извлечением, данные могут загружаться или полностью, или частично.
ELT и ETL: подробное сравнение
Чтобы помочь вам понять преимущества и ограничения обоих подходов к интеграции данных, мы выделили самые важные критерии, по которым будем сравнивать ETL и ELT.
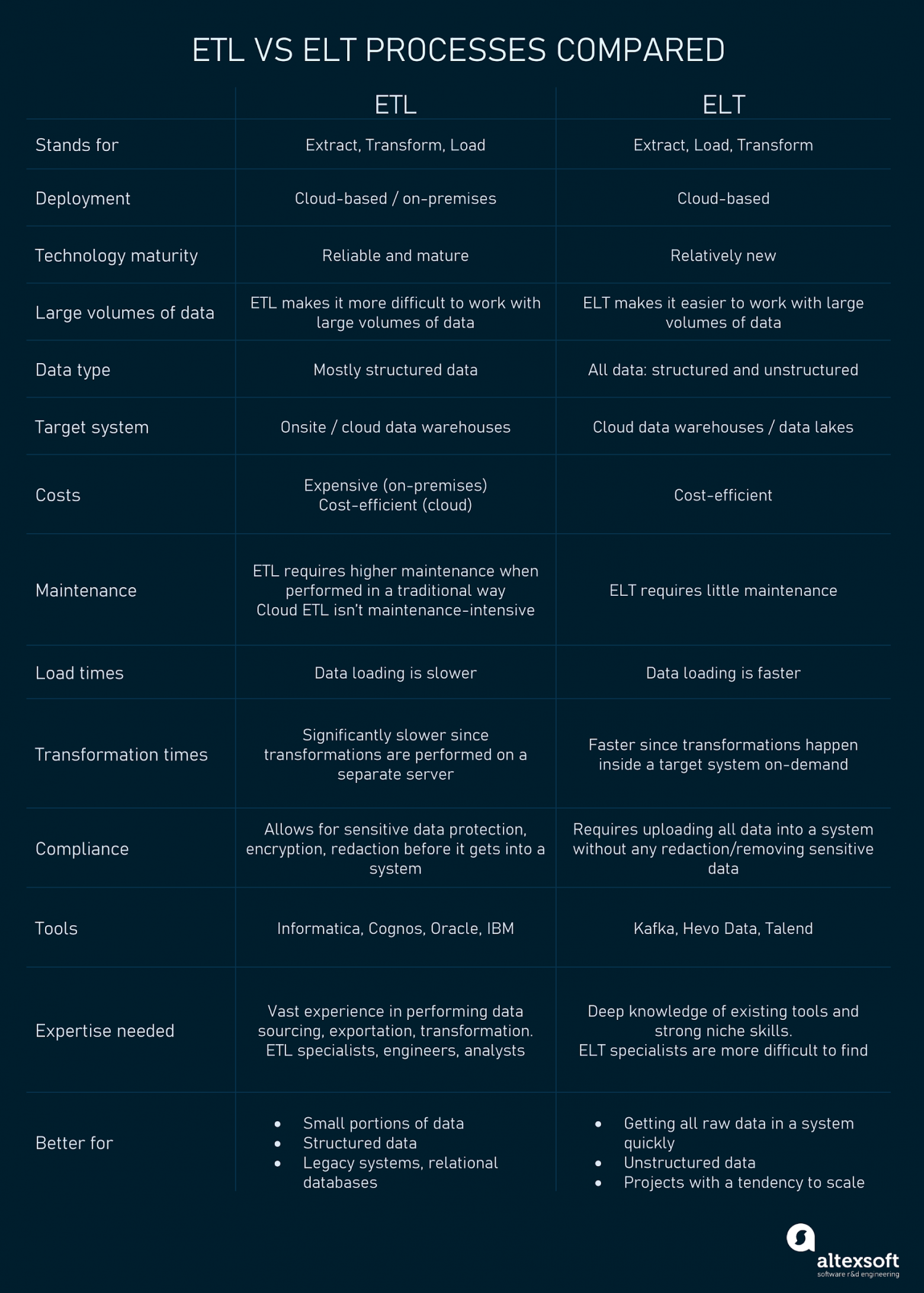
Зрелость технологий
ELT — относительно новая методология, поэтому для неё существует меньше наработок и профессиональных компетенций. Такие инструменты и системы всё ещё находятся на ранней стадии развития. Знающих процесс ELT специалистов сложнее найти.
С другой стороны, практика ETL уже довольно взрослая. Поскольку она используется уже долгое время, существует достаточное количество качественно разработанных инструментов, опытных специалистов и наработок.
Ключевой вывод: ETL надёжнее и взрослее.
Тип и размер данных
Наряду со структурированными данными, ELT позволяет обрабатывать большие объёмы нереляционных и неструктурированных данных, которые требуются для аналитики big data и бизнес-аналитики.
В случае, когда все исходные данные поступают из реляционных баз данных или когда их нужно тщательно очищать перед загрузкой в целевую систему, часто отдаётся предпочтение ETL.
Ключевой вывод: гибкий и масштабируемый ELT превосходит своего предка с точки зрения возможностей потребления больших массивов различных типов данных.
Поддержка хранилищ/озёр данных
ETL применяется при работе с хранилищами данных OLAP, легаси-системами и реляционными базами данных. Он не имеет поддержки озёр данных.
ELT — современный метод, который можно использовать с облачными хранилищами и озёрами данных.
Ключевой вывод: различные методы подходят в разных случаях использования.
Затраты
ELT не только экономически эффективнее по сравнению с высокопроизводительными решениями на мощностях компании, но и обеспечивает более низкие первоначальные расходы. Многие поставщики облачных услуг предлагают гибкие тарифные планы.
Архитектуры, в которых работают традиционные процессы ETL, могут быть затратными из-за первоначальных инвестиций в оборудование и затрат, связанных с мощностью движка преобразований. В то же время, современные облачные сервисы ETL обеспечивают гибкие тарифные планы на основании требований к масштабам использования.
Ключевой вывод: ELT относительно менее затратен по сравнению с ETL на мощностях компании.
Обслуживание
ELT — это облачное решение с автоматизированными функциями, не требующее или почти не требующее обслуживания. Все данные в нём готовы и могут по частям трансформироваться для аналитических целей.
Процессы ETL требуют более высокого уровня обслуживания, когда дело касается решений на мощностях компании с физическими серверами. Что касается облачных решений ETL с автоматизированными процессами, то ситуация в них не слишком отличается от ситуации в ELT: они не требуют особого обслуживания.
Ключевой вывод: с точки зрения обслуживания ELT превосходит ETL на мощностях компании.
Время загрузки
Благодаря встроенным возможностям обработки облачных решений, позволяющим загружать данные в «сырых» форматах без предварительных преобразований, ELT по сравнению с ETL снижает время загрузки.
При ETL процесс загрузки данных медленнее из-за необходимости преобразования данных на отдельном сервере обработки перед их поставкой в целевую систему.
Ключевой вывод: ELT обеспечивает более быструю загрузку.
Время преобразования
При ETL преобразования выполняются на отдельном сервере и происходят существенно медленнее, особенно при больших объёмах данных.
При ELT за преобразования отвечает целевая система. Благодаря разделению хранения и вычислений данные можно хранить в их исходном формате и преобразовывать по необходимости. Размер данных не влияет на скорость.
Ключевой вывод: при ELT преобразования занимают меньше времени.
Комплаенс
При ELT данные загружаются как есть, без предварительных сокращений и шифрования, что может сделать данные уязвимыми для взлома и нарушать стандарты комплаенса.
ETL позволяет редактировать, шифровать и удалять уязвимые данные перед их передачей в хранилище данных. Следовательно, компаниям проще защищать данные и соблюдать различные стандарты комплаенса, в том числе HIPAA, CCPA и GDPR.
Ключевой вывод: старый добрый ETL имеет преимущество с точки зрения комплаенса.
Инструменты и компетенции
Реализация обоих процессов требует глубоких знаний существующих инструментов и высоких навыков.
Из-за незрелости ELT специалистов с компетенциями в этой методологии найти сложно. Kafka, Hevo Data, Talend и некоторые другие программы предоставляют исчерпывающие возможности ELT и ETL.
Для выполнения таких процессов, как передача, экспорт, преобразования и миграция данных, требуются опытные специалисты по ETL. К счастью, в этой сфере найти компетентного специалиста проще. Одними из примеров традиционных инструментов ETL являются Informatica, Cognos и Oracle.
Ключевой вывод: инструменты и компетенции ETL на рынке представлены шире.
Подведём итог: оба процесса имеют свои преимущества и ограничения. Чтобы выбрать победителя в этой схватке (если он вообще есть), давайте рассмотрим возможные способы применения ETL и ELT.
Области применения ETL и ELT
Облачные хранилища данных открыли новые горизонты для интеграции данных, однако выбор между ETL и ELT в первую очередь зависит от потребностей компании.
Лучше использовать ETL, если...
- Вам нужно обеспечить соответствие установленным стандартам защиты уязвимых данных клиентов. Например, организации в сфере здравоохранения должны обеспечивать соответствие требованиям HIPAA Security Rule. Поэтому они могут выбрать ETL, чтобы маскировать, шифровать или удалять уязвимые данные перед загрузкой в облако.
- Вы работаете только со структурированными данными и/или с небольшими частями данных.
- В вашей компании работает легаси-система или реляционные базы данных на собственных мощностях. Примерами использования ETL в реальной жизни может быть извлечение данных электронных медицинских карт (EHR) при модернизации легаси-системы EHR: данные пациентов сначала должны быть селективно извлечены из легаси-системы, а затем преобразованы в нужный формат для новой системы.
Лучше использовать ELT, если...
- Самым важным фактором вашей стратегии является принятие решений в реальном времени. Скорость интеграции данных — ключевое преимущество ELT, поскольку целевая система способна выполнять преобразование и загрузку данных параллельно. Это, в свою очередь, позволяет генерировать аналитику практически в реальном времени.
- Ваша компания работает с огромными объёмами данных, как структурированных, так и неструктурированных. Например, транспортной компании, использующей телематические устройства в своих машинах, может требоваться обработка больших объёмов данных, генерируемых датчиками, видеорегистраторами, GPS-трекерами и так далее. Для обработки всех этих данных требуются огромные ресурсы, а также инвестиции в эти ресурсы. ELT позволяет экономить деньги и обеспечивать улучшенную производительность.
- Вы работаете с облачными проектами или гибридными архитектурами. Хотя современный ETL открыл свои двери облачным хранилищам данных, он всё равно требует отдельного движка для выполнения преобразований перед загрузкой данных в облако. ELT устраняет потребность в установке промежуточных движков обработки, а потому лучше подходит для облачных и гибридных систем.
- Вы собираетесь запускать проект с Big Data. ELT как раз и разрабатывался для достижения основных задач Big Data: объёма, разнообразия, скорости и достоверности.
- У вас есть команда дата-саентистов, которой требуется доступ ко всем «сырым» данным для их использования в проектах машинного обучения.
- Ваш проект будет масштабироваться и вы хотите воспользоваться преимуществами большой масштабируемости облачных хранилищ и озёр данных.
Будущее ETL и ELT
Технологии хранилищ данных стремительно развиваются. Современные облачные решения постепенно заменяют традиционные способы хранения данных. Предоставление облачными платформами масштабируемого хранилища данных и вычислительных ресурсов с гибкими тарифными планами позволяет хранить большие объёмы данных, обеспечивать к ним доступ и обрабатывать их. Поэтому всё большее количество компаний отходит от использования ETL в обслуживании конвейеров данных и выбирает метод ELT.
Распространение озёр данных тоже играет на руку ELT, потому что всё больше организаций предпочитают выполнять миграцию своих процессов работы с данными с собственных мощностей в облако. Управление озёрами данных выполняется при помощи платформ big data наподобие упомянутой выше Apache Hadoop или при помощи системы управления базами данных NoSQL. ELT также предпочтителен для команд дата-саентистов, поскольку предоставляет им возможность использовать «сырые» данные и преобразовывать их под собственные уникальные требования.
С учётом всего вышесказанного, ELT кажется логичным выбором будущего для создания эффективных потоков данных, поскольку он имеет множество преимуществ по сравнению с ETL. ELT выгоден экономически, гибок и требует меньшего количества ресурсов для обслуживания. Он подходит компаниям разного размера во множестве областей. ETL — это устаревший и медленный процесс, имеющий множество скрытых камней, о которые может споткнуться компания на пути к интеграции данных. Но как мы могли понять из описанных выше сфер использования, ETL невозможно заменить полностью.