


Качество проекта машинного обучения напрямую зависит от того, как вы подходите к решению 3 основных задач: сбора данных, их предобработки и разметки.
Разметка данных — это процесс присвоения меток или тегов набору данных для обучения ML-моделей. Например, для решения задачи распознавания изображений модель обучают на большом датасете с фотографиями или картинками, на каждой из которых проставлены метки. Они указывают, какие объекты изображены. Прописаны их основные признаки: цвет, форма, размер и другие характеристики.
Разметка данных — долгий и трудоемкий процесс. Выполняется или вручную человеком, или с привлечением автоматических алгоритмов и инструментов.
Виды разметки данных:
- разметка изображений;
- разметка видео;
- разметка текста;
- разметка аудио;
- разметка DICOM и NlfTI;
- разметка LIDAR.
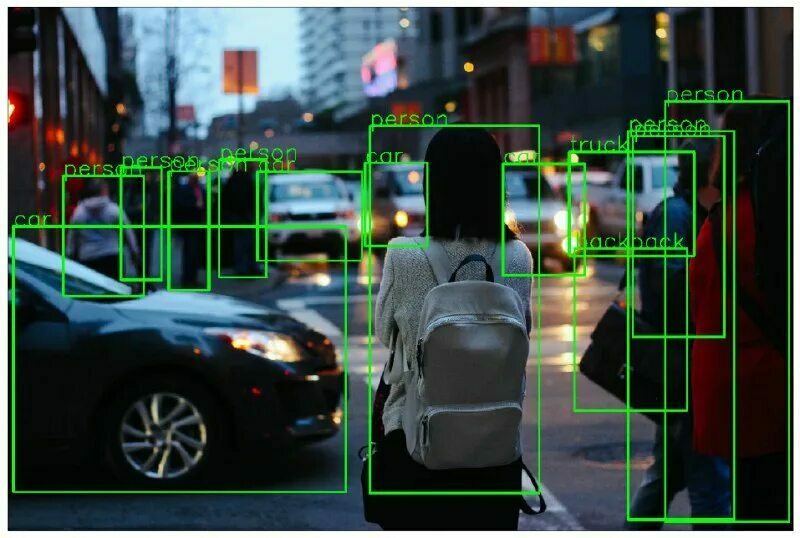
Разметка изображений
Разметка изображений — выделение объектов на картинке попиксельно и присваивание им меток согласно задаче. Например, для классификации, поиска объектов и т. д.
Сферы применения:
- медицинская диагностика — для обучения моделей и определения диагнозов на основе изображений, например рентгеновских или МРТ-снимков;
- автоматическое распознавание лиц — для тренировки таких алгоритмов, как системы аутентификации;
- автомобильная промышленность — для обучения беспилотных автомобилей, интеллектуальных парковочных систем;
- контроль качества — для систем контроля качества в производстве, например чтобы определять бракованные продукты на производственной линии и т. д.
Предположим, что мы создаем систему автоматического распознавания лиц по фотографии. Для этого нужно собрать датасет фотографий людей, разметить области интереса и прописать метаданные: пол, возраст, расу и т. д. Далее размеченный датасет отправляется в обучающий алгоритм. После успешного обучения система будет работать с точностью более 99 %.
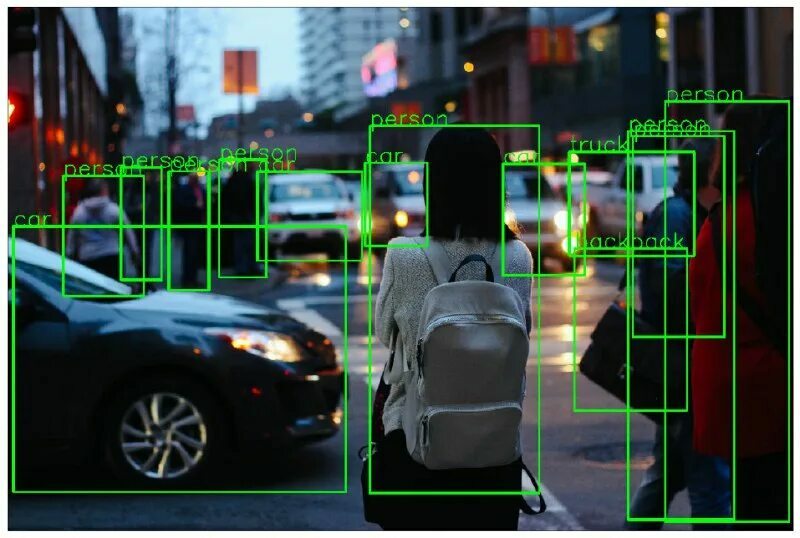
Разметка видео
Разметка видео — процесс аннотирования видеофайлов метками, которые описывают содержание и смысл того, что происходит в кадре.
Сферы применения:
- беспилотные автомобили — здесь компьютер обучается видеть дорожную обстановку и принимать решения, основанные на визуальных данных, в режиме реального времени;
- медицинские видео — модель учится диагностировать заболевания по видео;
- безопасность — данные видеорегистраторов и камер наблюдения часто используются в расследованиях преступлений, а разметка видео укажет на нужную информацию;
- видеоинтерактивные системы — для обучения распознаванию жестов и движений, позволяющих пользователю взаимодействовать с системой без клавиатуры и мыши, и т. д.
Разметка видео используется для обучения алгоритмов поиска и сортировки видеоконтента на сайтах. При этом в метках прописывается тематика, длительность ролика, качество картинки и звука и многое другое. Так пользователи смогут легко находить нужное им видео.
Разметка текста
Цель этого типа разметки — научить компьютер понимать текст на уровне человека. Его учат не только значению слов, но и контексту, тональности сообщений. В метках прописывают имена, даты, местоположение, категорию текста и другую информацию в зависимости от задачи.
Сферы применения:
- обработка естественного языка Natural Language Processing (NLP) — чтобы модель понимала сообщение, определяла контекст и смысл;
- классификация документов и текстов — чтобы компьютер мог определить категорию или тему исходного текста, например для автоматического индексирования или сортировки больших объемов данных;
- поиск информации по запросу — например, так работают поисковые системы. Пользователь пишет слово или фразу, алгоритм выдает подборку наиболее релевантных материалов;
- анализ тональности — положительные или негативные комментарии, например при сборе реакций аудитории на новый продукт в соцсетях.
Так, например, служба техподдержки может использовать систему классификации обращений по тематикам, где каждое нужно поместить в нужную категорию. Жалобы должны рассматриваться в первую очередь. Для обучения нужен датасет из примеров обращений. Каждое из них условно помечается «Жалоба», «Консультация» и т. д. После обучения модель поймет разницу и сможет автоматически классифицировать информацию в будущем.
Разметка аудио
В этом случае метки присваиваются аудиофайлам, чтобы модель машинного обучения смогла их обрабатывать и анализировать.
Сферы применения:
- обработка и распознавание речи. При правильной разметке алгоритм будет понимать слова, взаимосвязь между ними, общий смысл;
- обработка музыки. Например, при создании музыкальной библиотеки для классификации жанров, разделения инструментов, выделения ритмов и мелодий, других задач;
- медицинские и научные исследования. Модель учится понимать звуки, которые сигнализируют о наличии заболевания, патологии или изменений окружающей среды, и передает информацию человеку или принимает решение самостоятельно;
- обработка звука в реальном времени. Например, в системах безопасности, которые реагируют на звук разбитого стекла или звонок в дверь.
Например, у вас есть запись интернет-конференции или заседания суда. И вам нужно разделить ее по спикерам. Для этого модель машинного обучения обучается на размеченных аудиофайлах, где прописано, кто говорит и когда. В результате в дальнейшем алгоритм сможет определить и выделить речь каждого спикера внутри новых записей с высокой точностью без участия человека.
Разметка DICOM и NlfTI
DICOM (Digital Imaging and Communications in Medicine) и NIfTI (Neuroimaging Informatics Technology Initiative) — форматы файлов для хранения медицинских изображений, таких как магнитно-резонансная томография (МРТ), компьютерная томография (КТ). DICOM-файлы могут быть обработаны и проанализированы в различных медицинских информационных системах, в том числе машинного обучения.
NIfTI — формат файлов, используемых в нейрообразовании для хранения трехмерных массивов данных, представляющих изображения. Этот формат файлов используется в машинном обучении для обработки и анализа медицинских изображений, таких как МРТ.
Например, в диагностике искусственный интеллект может быть обучен на основе картинок, сохраненных в формате DICOM. Так можно научить модель распознавать злокачественные новообразования по медизображению.
Искусственный интеллект также может использоваться для обработки МРТ-изображений, сохраненных в формате NIfTI, для обнаружения и анализа изменений в мозговых структурах, связанных с деменцией или другими нарушениями функционирования мозга.
Разметка LIDAR
LIDAR (Light Identification, Detection and Ranging) — метод дистанционного зондирования, который использует лазерный луч для измерения расстояния и создания точных изображений и/или карты окружающей среды. При разметке облака точек классифицируются для их последующего использования в приложениях для беспилотного транспорта, робототехники и других областей.
Сфера применения:
- автономные транспортные средства. LIDAR-датчики устанавливаются на беспилотных автомобилях для создания точных трехмерных моделей окружающей среды и обнаружения препятствий. Эти данные используются для обучения моделей машинного обучения, которые помогают транспортному средству принимать решения и управлять движением;
- спутниковые карты. LIDAR применяется в обработке данных спутниковых карт для формирования точных 3D-моделей поверхности Земли. На их основе создают цифровые карты высокого разрешения;
- робототехника. LIDAR обучает роботов идентифицировать объекты, определять их расположение и форму, создавать трехмерную карту и на основе нее рассчитывать свой путь;
- геодезия и картография. LIDAR-данные используются для создания точных цифровых карт и моделей местности, например для градостроительств, геологии, лесного хозяйства.
Примером использования разметки LIDAR для обучения модели в реальности может быть автономный автомобиль или беспилотный летательный аппарат (БЛА), который использует данные, созданные с помощью LIDAR, для построения 3D-карт окружающей среды и определения своего положения в ней.
Для обучения автономной системы управления используются облака точек, которые содержат точную информацию о форме объектов вокруг транспортного средства и об их расстоянии от него. Эти данные затем размечаются — маркируются, например, как «машина», «дерево», «человек». Далее модели машинного обучения извлекают признаки и обучаются классифицировать и детектировать объекты перед ними. Эта информация необходима для безопасного движения беспилотного автомобиля. Он «понимает», что перед ним, и принимает соответствующее решение.

Как размечаются данные?
Разметка может быть выполнена как вручную, так и с использованием автоматических методов. Ручную выполняют эксперты — люди. Этот метод дает максимальную точность, но может быть трудоемким и дорогим, особенно при большом объеме данных.
Автоматическую разметку выполняют алгоритмы машинного обучения без участия человека. Их обучают распознавать и размечать информацию на основе специально подготовленных датасетов. Также существуют методы для автоматической аугментации данных, например генерации дополнительных изображений на основе существующих.
Возможна полуавтоматическая разметка: например, сначала работает алгоритм, а потом человек.
Что лучше? Безусловно, по качеству лучшей будет ручная разметка. Ее выполняют специалисты с экспертными знаниями в определенной области, поэтому ошибки практически отсутствуют, а модель после обучения дает высокие результаты. Ее минус — если у компании-исполнителя недостаточно разметчиков, требуется много времени.
Самая быстрая — автоматическая разметка. Но после нее часто нужно дорабатывать данные вручную: «сырой» материал не даст нужных результатов при обучении модели.
Крупные компании по сбору и разметке данных, такие как Training Data, имеют максимум возможностей для работы с чувствительным контентом. Благодаря большой команде разметчиков мы закрываем 90 % проектов раньше срока. Соберем тестовый датасет по вашей задаче бесплатно, чтобы вы могли убедиться в качестве данных лично.