Сегментация данных — это процесс разделения предоставленных данных на группы (сегменты), основанные на заданных критериях, чтобы улучшить точность и эффективность модели. Для примера возьмем медицину — сегментацию заболеваний кожи. Предположим, что у нас есть датасет с большим количеством фотографий кожных заболеваний, таких как акне, псориаз, экзема и т. д. Задача: обучить модель распознавать и классифицировать эти заболевания. Для этого требуется:
- предварительная обработка. Из набора исключаются некачественные или поврежденные изображения;
- сегментация данных. Изображения разделяют на группы и размечают для классификации по типу заболевания;
- обучение модели. Каждая группа данных используется для обучения отдельной модели, специализирующейся на определении соответствующего заболевания;
- валидация результатов. Применяется для оценки точности каждой обученной модели и настройки гиперпараметров.
Сегментация данных в этом примере позволяет получить более точные модели машинного обучения, специализирующиеся на определении разных типов кожных заболеваний.
Виды сегментации данных
- Семантическая. На изображении выделяются области, которые соответствуют объектам или их классам. Например, при обучении беспилотного автомобиля семантическая сегментация требуется для правильного обнаружения и определения объектов на дороге, таких как другие автомобили, пешеходы, дорожные знаки, светофоры, разметка дороги и др.
- Сегментация на основе инстансов. Объекты разделяются на отдельные экземпляры, даже если относятся к одному классу. Пример: определение беспилотным автомобилем других машин, чтобы правильно их классифицировать и выявлять точные контуры каждого для безопасного движения.
- Сегментация изображений на основе текстур. Выделение объектов, опираясь на их текстурные характеристики. Например, на фотографии различных тканей, расположенных вплотную друг к другу, алгоритм будет определять «хлопок», «шелк», «кожу» на основании их текстуры.
- Сегментация звуковых сигналов. Аудиозаписи разделяются на сегменты по таймингу или по спикеру. Например, в звуковой записи конференции с выступлением нескольких участников можно идентифицировать и выделить фрагменты по голосам.
Зачем размечать данные на основе ML?
Парсинг и правильная разметка изображений, видео и звуков для датасета требует большой команды разметчиков. И даже в этом случае процесс займет много времени. Модель машинного обучения дополняет человека, повышая скорость разметки и качество результата.
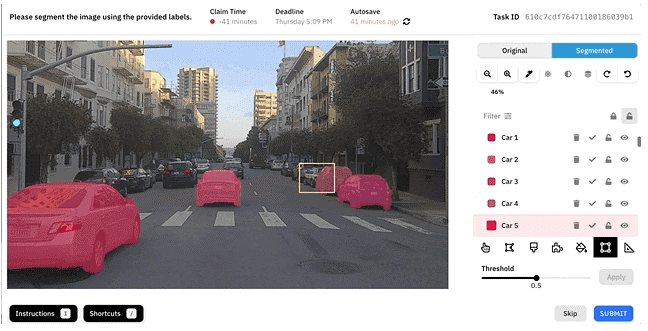
ML-модель может сократить время сегментации данных на 30–50 %. Человек создает ограничивающий прямоугольник, модель попиксельно распознает объект в нем. Остается только присвоить соответствующую метку.
Например, перед нами снимок улицы. Его нужно разметить для обучения беспилотного автомобиля. Для этого нужно выделить каждый объект: не только контур, а весь, по пикселям. Т. е. выделяется видимый участок дороги, транспортные средства, дорожная разметка, знаки и т. д. Модель, способная идеально сегментировать объекты, пусть даже не полностью, все равно значительно экономит время разметчиков. Кроме того, есть возможность настроить точность ее работы в реальном времени, меняя параметры и входную информацию для лучшего результата. Также модели могут обучаться на размеченных примерах и на обратной связи от разметчиков, повышая свою производительность с течением времени.
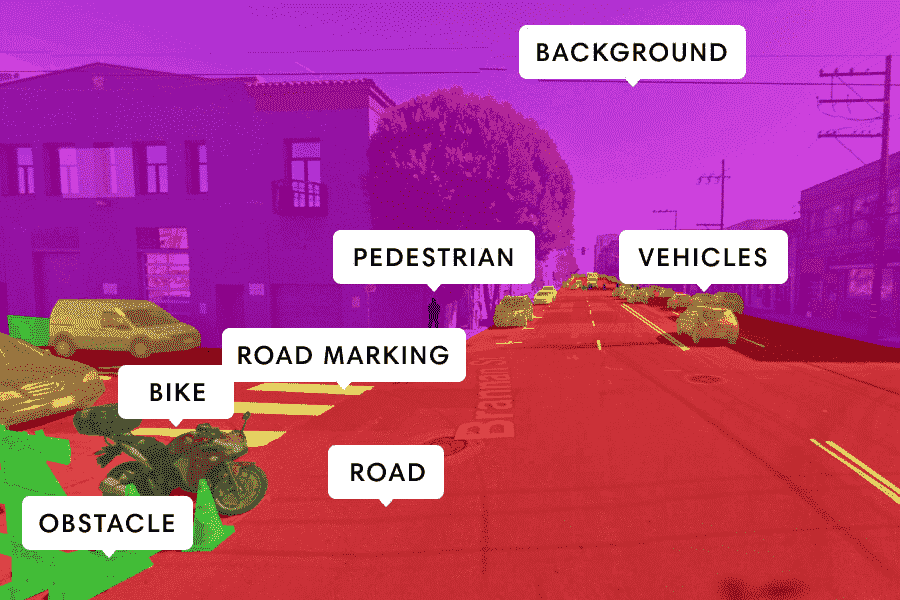
Задача разметки семантической сегментации
Задача разметки семантической сегментации — распознать и классифицировать каждый пиксель изображения согласно заданному набору классов. В отличие от сегментации на основе инстансов, которая выделяет каждый объект на изображении целиком, семантическая обобщает и классифицирует пиксели на основе их принадлежности к определенному классу (например, дорога, здание, автомобиль). Для этого при разметке используются разноцветные маски, которые наглядно показывают отношение каждого пикселя к классу объектов.
Далее размеченные данные используются для обучения алгоритмов ML, например, сверхточных нейронных сетей (CNN). Цель в итоге: научить модель самостоятельно определять и классифицировать объекты на изображении, в том числе по новым типам данных.
Для улучшения качества работы модели могут быть использованы алгоритмы, основанные на глубоком обучении, такие как U-Net, DeepLab и SegNet. Они позволяют получать более точные результаты, поэтому семантическая сегментация применяется в областях, где точность результата может быть критичной. Например, в беспилотном транспорте, медицинской диагностике.
Какие инструменты применяются для сегментации данных?
Существуют различные инструменты и алгоритмы, как свободно распространяемые, так и коммерческие. Среди них:
- OpenCV. Библиотека компьютерного зрения с открытым исходным кодом, доступная для множества языков программирования, таких как Python, C++, Java и других;
- ITK: Insight Segmentation and Registration Toolkit. Это система с открытым исходным кодом, разработанная для 2D- и 3D-сегментации изображений;
- ImageJ/Fiji. Бесплатный инструмент для анализа изображений, особенно популярный в биомедицинских исследованиях;
- Labelbox.com. Онлайн-платформа для разметки данных с возможностью совместной работы.
Один из самых удобных инструментов для автоматической сегментации данных презентовал Labelbox: Auto-Segment 2.0. По заявлению разработчика, это самая быстрая и точная семантическая сегментация в мире. Главной особенностью Auto-Segment 2.0 является использование растрового представления данных о маске для процесса сегментации, а не векторного. Растровая система рендеринга обрабатывает каждый пиксель изображения индивидуально, чтобы определить, принадлежит ли он объекту или фону. Может адаптироваться для рабочих процессов разной сложности и объема, от маленьких проектов до крупных корпоративных задач. Полуавтоматический подход совмещает автоматическую обработку и человеческую экспертизу, что экономит время и ресурсы на разметке данных.